
第1章 测试概述
1.1 Fault Error Failure
| 概念 | 中文 | 含义 |
|---|---|---|
| Fault | 缺陷 / 静态缺陷 | 软件中静态存在的错误代码、错误设计、错误逻辑 |
| Error | 错误状态 | fault 被执行后,导致程序内部状态不正确 |
| Failure | 失效 / 失败 | 错误状态传播到外部,使输出或行为不符合需求 |
Software Fault 是软件中的静态缺陷;
Software Error 是某个 fault 表现出来的错误内部状态;
Software Failure 是相对于需求或预期行为而言的外部错误行为。
1.2 PIE Model
PIE Model 解释的是:一个缺陷要被测试发现,必须连续满足三个条件。
| 字母 | 含义 | 解释 |
|---|---|---|
| P / E:Execution / Reachability | 执行 / 可达 | 测试必须执行到含有 fault 的代码位置 |
| I:Infection | 感染 | 执行 fault 后,程序内部状态必须变错,即产生 error |
| P:Propagation | 传播 | 错误内部状态必须传播到外部输出,形成 failure |
执行 感染 传播
简单可以理解为3步骤:
- fault 所在位置必须被执行到;
- 程序状态必须变成不正确;
- 被感染的状态必须传播,使某个输出不正确。
==Fault → Error → Failure== 但注意,这条链条可能在任何一步断掉。
1.3 讨论:是否存在永远无法发现的缺陷
==没有执行到 fault:代码里有缺陷,但测试输入没有走到那段代码。==
if (x > 0) {
// 这里有 fault
}如果测试只有x <= 0,那么该fault永远不会被执行。
==执行到了 fault,但没有产生 error==
用平均值程序
for (int i = 1; i < length; i++) // 应该是 i=0
{
sum += numbers[i];
}
mean = sum / (double) length;当输入[0, 4, 5]的时候,刚好平均值和正确的一样
==产生了 error,但没有传播成 failure==
就是瞎猫撞死老鼠
最终输出刚好和测试预言一样
| 类型 | PIE 哪一步失败 | 说明 |
|---|---|---|
| 不可达缺陷 | Execution 失败 | 测试没有执行到 fault 所在代码 |
| 偶然正确 | Infection 失败 | 执行了 fault,但内部状态没有变错 |
| 错误未传播 | Propagation 失败 | 内部已经错了,但最终输出仍然正确 |
| 等价缺陷 / 等价变异 | 对所有测试都不产生可观察 failure | 代码形式不同,但外部行为完全一样 |
| 缺少测试预言 | Failure 无法判断 | 输出是否错无法自动判断,即 oracle 不存在或不充分 |
设计3个测试用例
int avg3(int[] a) {
int sum = 0;
// fault: 应该从 i = 0 开始,但错误地从 i = 1 开始
for (int i = 1; i < 3; i++) {
sum += a[i];
}
return sum / 3;
}| 测试 | 输入 | 正确 sum | 实际 sum | 正确输出 | 实际输出 | 结果 |
|---|---|---|---|---|---|---|
| t1 | [0, 4, 5] | 9 | 9 | 3 | 3 | executes fault, but no error |
| t2 | [1, 2, 2] | 5 | 4 | 1 | 1 | error, but no failure |
| t3 | [3, 4, 5] | 12 | 9 | 4 | 3 | failure |
1.4 减少缺陷的自动化方法
- Static Analysis 静态分析
- Testing 测试
- Verification 验证
静态分析
静态分析:通过扫描代码中的可疑模式,识别软件中的特定问题,例如内存泄漏。
局限性
- 能够发现的问题类型有限。
- 可能产生误报。误报:工具报告显示有问题,但实际上这里没有缺陷。
测试
测试:向软件输入数据并运行它,观察其行为是否符合预期。
局限性
- 不可能覆盖所有可能的执行情况。
- 需要测试预言机,也就是判断输出是否正确的依据。
- 输入域可能是无限的。
验证
形式化验证:考虑程序所有可能的执行情况,并用形式化方法证明程序是否正确。
局限性
- 很难得到严格的形式化规格说明。
- 大多数现实世界中的程序验证成本太高,难以完整证明。
1.5 测试的概念
测试用例:测试输入 + 测试预言 + 测试环境
Test Case = Test Input + Test Oracle + Others
- 测试用例 Test Case
- 测试输入 Test Input
- 测试数据 Test Data
- 测试预言机 Test Oracle
- 期望输出 Expected output
- 测试套件 Test suite
- 测试脚本 Test script
- 测试驱动 Test driver
1.6 测试 vs. 调试
测试是通过执行测试并观察失效来揭示 bug。
调试是通过定位、理解并修正缺陷来修复 bug。
Testing and Debugging
测试负责发现问题,调试负责修复问题。
1.7 验证 vs. 确认
确认 Validation
确保一个产品、服务或系统满足客户及其他相关利益方的需求。它通常涉及外部客户的验收和适用性判断。
确保产品、服务或系统满足客户和其他相关方的真实需要。
它通常涉及外部客户的验收和适用性判断。
验证 Verification
评估一个产品、服务或系统是否符合规定、需求、规格说明或强加条件。它通常是一个内部过程。
评估产品、服务或系统是否符合规定、需求、规格说明或约束条件。
它通常是内部过程。
确认:
- 我们构建的是不是正确的产品?
- X 是我们本来就应该构建的东西吗?它是否满足高层需求?
验证:
- 我们是否在正确地构建产品?
- 假设我们应该构建 X,那么我们的软件是否在没有 bug 或缺口的情况下实现了目标?
1.8 静态测试 vs. 动态测试
Static Testing vs. Dynamic Testing
静态测试:不执行程序。
动态测试:执行程序。
代码审查、静态分析属于静态测试;
单元测试、集成测试、系统测试通常属于动态测试。
1.9 V Model
开发过程和测试过程一一对应的模型。
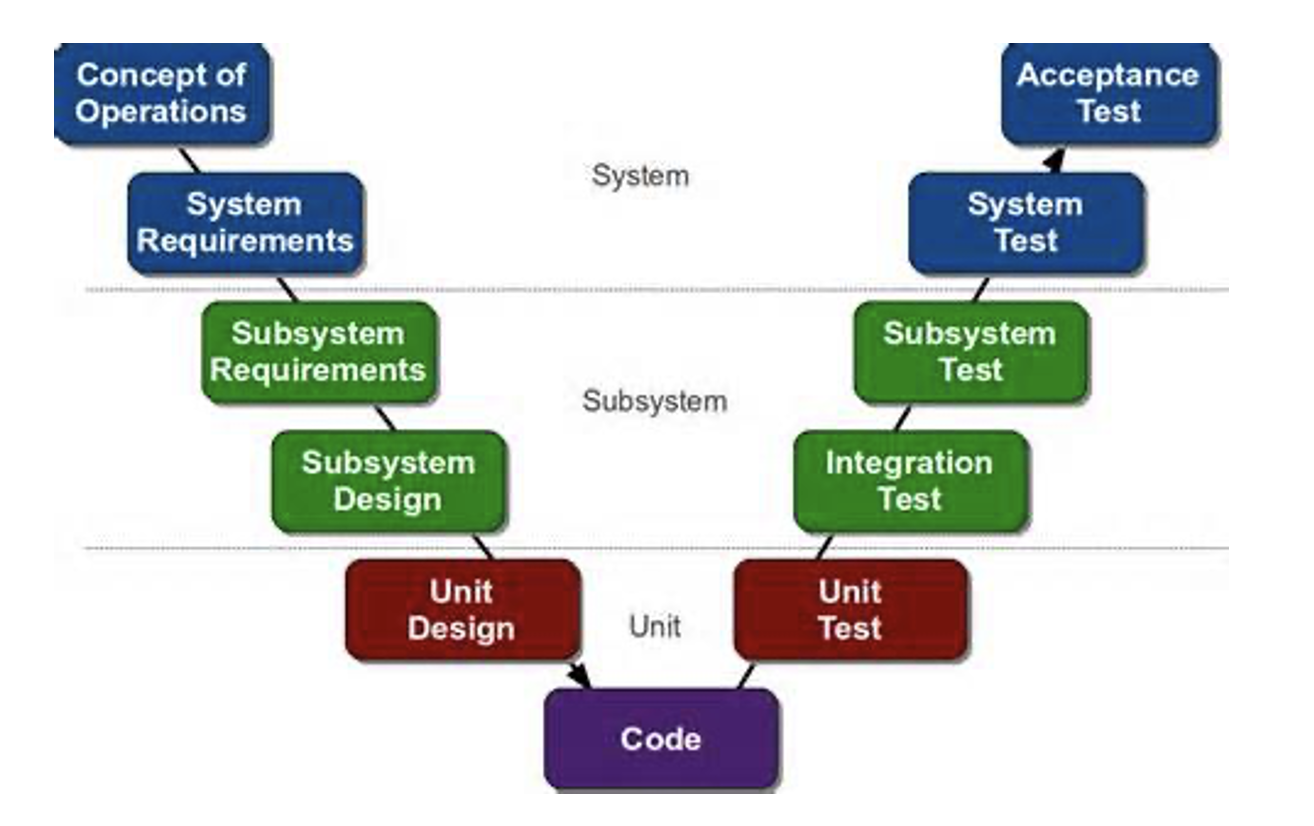
测试层次分成了几个粒度:单元测试、集成测试、系统测试、验收测试。其中单元测试是测试单个模块;集成测试是测试模块之间的交互;系统测试是开发人员从整体上测试系统;验收测试是用户根据需求验证系统,通常没有形式化测试用例。
需求分析 验收测试
↓ ↑
概要设计/系统设计 系统测试
↓ ↑
详细设计/模块设计 集成测试
↓ ↑
编码实现 -------------> 单元测试每个开发阶段都应该有对应的测试阶段。
第2章 单元测试
2.0 为什么要进行单元测试
采用 分而治之 的方法:
- 将系统拆分为多个单元。
- 分别调试每个单元。
- 缩小 bug 可能存在的范围。
- 不希望在其他单元中到处追踪 bug。
也就是说,单元测试的核心思想是:先保证小模块正确,再逐步构建更大的系统。
2.1 如何进行单元测试
按层次构建系统:
- 从不依赖其他类的类开始测试。
- 然后在已经测试过的类的基础上,继续测试更高层的类。
好处:
- 避免编写过多的 mock 类。
- 当测试某个模块时,它依赖的模块已经比较可靠。
2.2 参数化的测试用例
参数化测试的本质是:同一套操作步骤,只换输入和期望输出。
参数化测试的做法是:
只写一个测试逻辑 test m1(),然后把不同输入作为参数传进去。
同一个测试方法 + 多组测试数据。
@RunWith(Parameterized.class)
public class IMathTestJUnitParameterized {
private IMath tester;
private int input;
private int expectedOutput;
/** 构造方法:接收每一组输入-输出对 */
public IMathTestJUnitParameterized(int input, int expectedOutput) {
this.input = input;
this.expectedOutput = expectedOutput;
}
@Before
/** 创建测试夹具的初始化方法 */
public void initialize() {
tester = new IMath();
}
@Parameterized.Parameters
/** 存储输入-输出对,也就是测试数据 */
public static Collection<Object[]> valuePairs() {
return Arrays.asList(new Object[][] {
{ 0, 0 },
{ 1, 1 },
{ 2, 1 },
{ 3, 1 },
{ 100, 10 }
});
}
@Test
/** 参数化的 JUnit 测试方法 */
public void testIsqrt() {
assertEquals(
"square root for " + input + " ",
expectedOutput,
tester.isqrt(input)
);
}
}但是,并不是所有测试都可以抽象成参数化测试。
==参数化测试适用于相同测试逻辑 + 不同测试数据==
==但如果不同测试用例内部调用的方法顺序不同,或者测试流程本身不同,就不适合简单抽象成参数化测试。==
例如:
public class ArrayList {
...
/** 返回当前 list 的大小 */
public int size() {
...
}
/** 向 list 中添加一个元素 */
public void add(Object o) {
...
}
/** 从 list 中移除一个元素 */
public void remove(int i) {
...
}
}反例 测试 ArrayList
// 测试用例1
list.add(1);
list.remove(0); // ← 调用了 remove
assertEquals(0, list.size());
// 测试用例2
list.add(1);
list.add(2);
list.add(3); // ← 没有 remove,add 了三次
assertEquals(3, list.size());这两个用例操作步骤根本不一样,无法抽象成统一的 (input → expectedOutput) 结构,所以没办法参数化。
第3章 白盒测试
3.1 语法可达 vs. 语义可达
语法可达:只要图中存在一条路径,就叫语法可达。
语义可达:如果存在一个测试用例可以真正执行这条路径,就叫语义可达。
注意:语法上可达,但是语义上可能不可达。
void f(int x) {
if (x > 0) {
System.out.println("A");
}
if (x < 0) {
System.out.println("B");
}
}3.2 结构化覆盖
顶点覆盖 Vertex Coverage
如果对于图 中每一个语法可达的顶点 ,测试集合 执行出的路径集合 中都存在一条路径 ,使得 覆盖 ,则称测试集合 满足顶点覆盖。
边覆盖 Edge Coverage
如果对于图 中每一条语法可达的边 ,测试集合 执行出的路径集合 中都存在一条路径 ,使得 覆盖 ,则称测试集合 满足边覆盖。
覆盖多条边 Covering Multiple Edges
边对覆盖要求覆盖边的组合,也就是连续两条边组成的路径。
完全路径覆盖 CPC Complete Path Coverage
TR(测试需求集合)包含图 G 中的所有路径。
n-路径覆盖 nPC n-Path Coverage
TR 包含图 G 中所有长度不超过 n 的可达路径(含长度 n)。
| 缩写 | n 值 | 含义 |
|---|---|---|
| VC(顶点覆盖) | n=0 | 只需经过每个节点 |
| EC(边覆盖) | n=1 | 覆盖每条边(长度为1的路径) |
| EPC(边对覆盖) | n=2 | 覆盖每对相邻边(长度为2的路径) |
| CPC(完全路径覆盖) | n=∞ | 覆盖所有路径 |
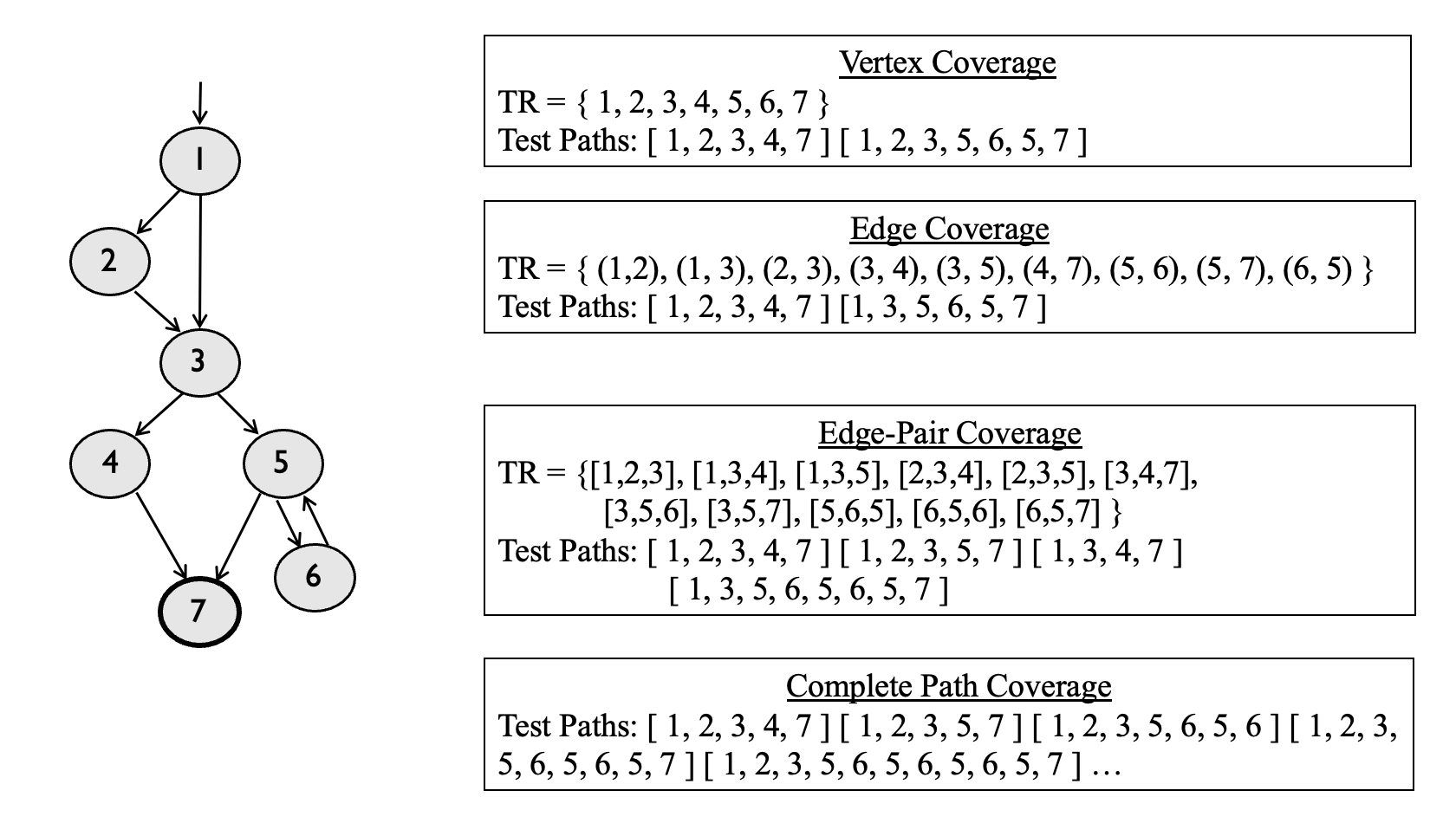
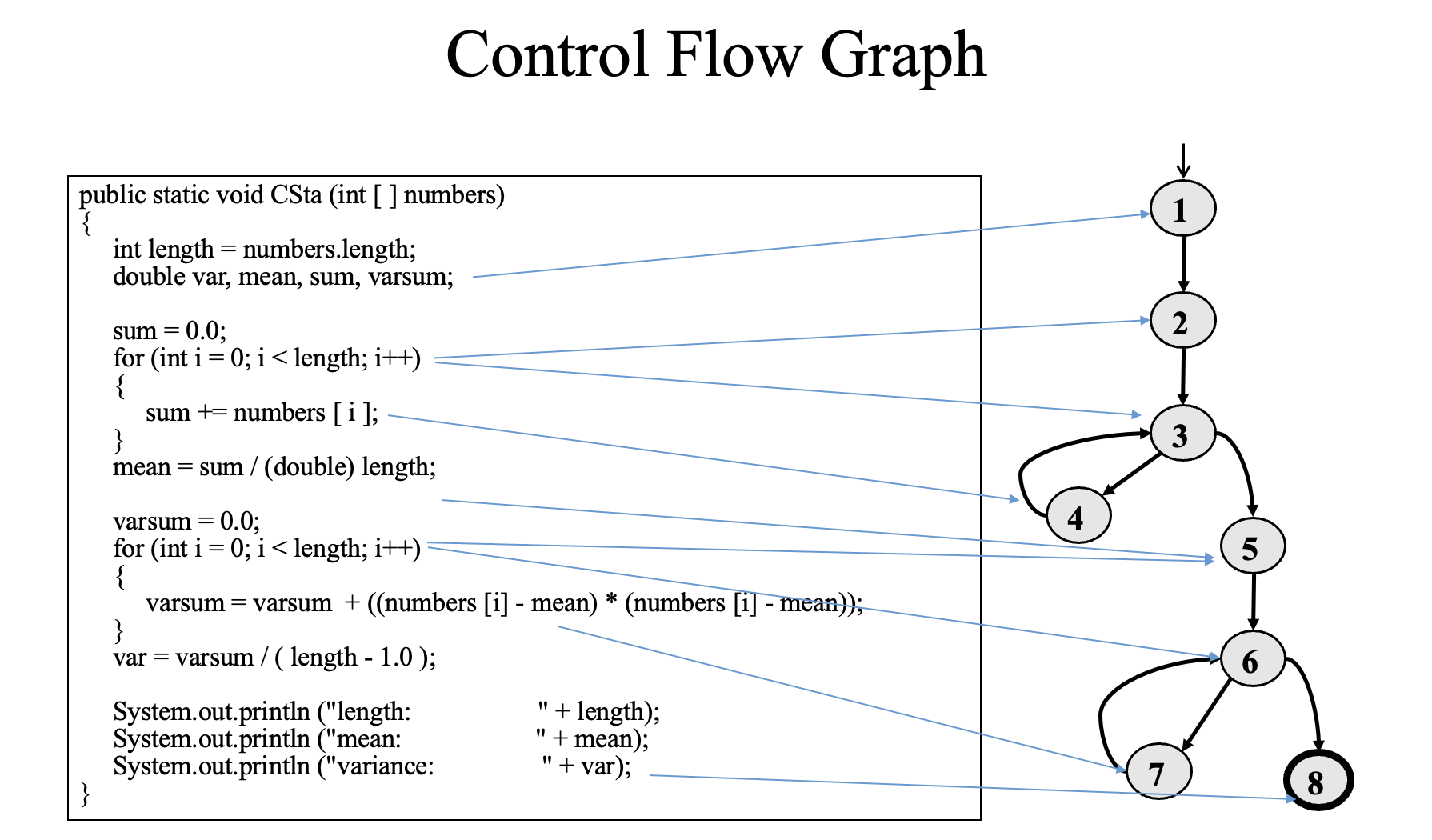
3.3 CPC Complete Path Coverage
CPC 无法保证 100% Bug-Free
核心原因:覆盖路径 ≠ 检验正确性
CPC 只保证"所有路径都被执行过",但它无法保证测试用例的期望输出是正确的。
例如:
public int sum(int x, int y) {
return x - y; // ← Bug!应该是 x + y
}使用assertEquals(1, sum(1, 0))测试
测试通过
Path coverage(CPC):100%
但是没有发现bug
局限1 同样的CPC 含循环时路径数无限 ♾️
因为图中有 5→6→5 的环,循环几次都是合法路径,所以 TR 是无限集合,根本无法完成测试。
局限2 实际中不可行路径(Infeasible Path)
局限 3 只关注"结构",不关注"语义"
CPC 是白盒方法,只看程序的控制流图(CFG)结构,不理解程序的业务逻辑和正确语义,所以即使全覆盖也可能漏掉逻辑性错误。
3.4 CC 和 DC
DC: Decision Coverage 判定覆盖
要求判定的结果至少执行一次 true,至少执行一次 false。
对于((x > 5) && (y > 0))需要让整个decision的结果分别为true和false
CC: Condition Coverage 条件覆盖
要求每个 condition 都至少取到一次 true,至少取到一次 false。
需要满足:
(x > 5):true 和 false
(y > 0):true 和 false
CC 和 DC 没有包含关系,互不蕴含。
3.5 修正条件/判定覆盖 MC/DC
MC/DC全称是:Modified Condition/Decision Coverage
它比 C/DC 更严格,核心思想是:每一个基本条件都应该被证明能够 独立影响整个判定结果。
MC/DC 要求每个条件都能分别执行到 true 和 false,并且每个条件都能够 独立影响整个判定结果。
也就是说,对于一个 decision 中的每个 condition,都要证明:
当其他条件保持不变时,只改变这个条件的取值,整个 decision 的结果也随之改变。
To test if A and (B or C)
构造如下测试表
| Case | A | B | C | B || C | Decision = A && (B || C) |
|---|---|---|---|---|---|
| case 1 | T | T | F | T | T |
| case 2 | F | T | F | T | F |
| case 3 | T | F | F | F | F |
| case 4 | T | F | T | T | T |
Condition A: case 1 and case 2
Condition B: case 1 and case 3
Condition C: case 3 and case 43.6 短路会影响 MC/DC
MC/DC 在有**短路求值(short-circuit evaluation)**的语言里,可能“表面上满足了 MC/DC”,但实际上某些条件根本没有被真正求值,所以没有达到严格意义上的条件独立影响覆盖。
MC/DC 最初是为逻辑运算符不短路的语言设计的;而 C、C++、Java 的短路逻辑运算符只会在某个条件可能影响整个判定结果时才继续求值,因此 MC/DC 会受到程序中判定结构的影响。
解决方案:
方案一:把复合判定拆成嵌套 if
3.7 简单路径和主路径和回路路径
简单路径:一条路径从节点ni到nj的路径,如果除了首位节点可以相同之外,没有任何节点重复出现,就叫作简单路径
换句话说,简单路径内部不能有环,但“起点=终点”的环本身可以是简单路径。
主路径:主路径是不作为任何其他简单路径的真子路径的简单路径
也就是说,主路径首先必须是简单路径;其次它还要“尽可能长”,不能被包含在另一条更长的简单路径里面。
Round-Trip Path:起点和终点相同的 Prime Path。
第5章 黑盒测试
5.1 随机测试中的问题
- 定义输入域
- 随机机制
- 随机性与完整服务
随机测试主要有几个问题:
- 必须定义输入域
- 必须设计随机机制
- 随机性本身也有质量问题
5.2 自适应随机机制 ART Adaptive Random Testing
它是在普通随机测试基础上的改进。普通随机测试每次直接随机选一个测试输入,而 ART 会尽量让新生成的测试输入远离已经执行过的测试输入,从而提高测试输入的分散性和多样性。
随机生成一个输入 t,运行 t,并将 t 加入测试集合 T
while(尚未达到停止条件)
随机生成 k 个候选输入 c1, …, ck
对每一个候选输入 ci:
计算 ci 到已有测试集合 T 的最小距离 di
end for
选择最小距离 di 最大的那个候选输入 t
运行 t,并将 t 加入测试集合 T
end while| 符号 | 含义 |
|---|---|
| min | 对于某个候选输入ci,计算它到已执行测试用例集合T中所有点的距离,取其中的最小值。代表ci距离最近的已测点有多远 |
| max | 在所有的候选输入c1...cn中,选出di最大的那个作为下一个测试用例,代表选最孤立、离已测区域最远的那个。 |
三种典型失败模式:
- Block 模式:失败区域是一个连续矩形块
- Strip 模式:失败区域是一个条带
- Points 模式:失败区域是离散点
ART 的问题
- 距离
- 开销
- 维度灾难
距离怎么定义:对于数值输入,距离可以用欧氏距离、曼哈顿距离等。但对于字符串、对象、文件、GUI 操作序列等复杂输入,距离就不容易定义。
计算开销更大:普通随机测试生成一个输入就直接执行;ART 需要生成多个候选输入,并且计算它们与已有测试集合的距离,所以成本更高。
维度灾难:当输入参数很多时,输入空间维度变高,距离计算和“分散性”的效果都会变差。二维空间中看起来很直观的“远近”,在高维空间里会变得复杂。
ART 效果不好的场景
- 失败区域是 Point Pattern(离散点分布)
- 高维输入(Curse of Dimensionality,维度诅咒)
- 计算开销(Overhead)本身是问题
5.3 等价类划分
等价类划分的方法
等价类划分域,本质上是:把输入域 D 分成若干个互不重叠、合起来又能覆盖整个输入域的小区域,也就是等价类。课件中对划分有两个要求:各个块两两不相交,并且所有块合起来覆盖整个域 D。
- 先确定输入域 D
- 找划分依据,也叫特征 characteristic
- 保证“互不重叠”
- 保证“完全覆盖”
- 每个等价类中选代表值
等价类划分域就是根据输入参数的取值范围、类型、业务规则或功能语义,把输入域 D 划分为若干个等价类。划分后的等价类必须满足两个条件:第一,等价类之间互不重叠;第二,所有等价类合起来能够覆盖整个输入域。然后从每个等价类中选择一个或少量代表值作为测试用例。
等价类设计的方法
- 基于接口的方法:直接从程序的输入参数本身出发,对每个输入参数单独划分等价类。
- 基于功能的方法:从程序的预期功能或行为出发,根据需求、语义和业务规则来划分等价类。
基于接口:
判断三角形
| 输入参数 | 等价类示例 |
|---|---|
| a | >0、=0、<0 |
| b | >0、=0、<0 |
| c | >0、=0、<0 |
这种方法比较机械、简单,依赖输入语法,但缺点是容易忽略参数之间的关系。比如它知道三条边都大于 0,但不一定自然考虑 a + b > c 这种三角形语义关系。
基于功能:
它不是孤立看每个参数,而是看这些输入组合在功能上代表什么情况。
例如三角形程序中,三个整数共同表示一个三角形,那么可以按几何意义划分:
| 功能语义 | 等价类 |
|---|---|
| 三角形类型 | 一般三角形 |
| 三角形类型 | 等腰三角形 |
| 三角形类型 | 等边三角形 |
| 非法情况 | 不能构成三角形 |