
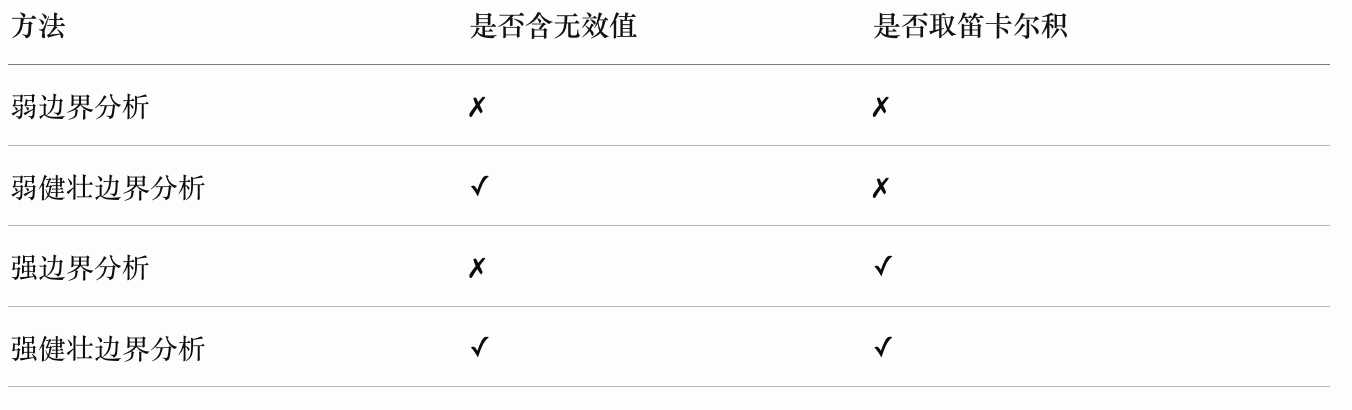
等价类划分 Equivalence Partitioning
等价类划分可以应用于多个测试层级:
- 单元测试
- 集成测试
- 系统测试
无须自动化工具,相对容易应用
可以灵活调整流程,以获得更多或者更少的测试用例。
输入域
程序的输入域包含该程序所有可能的输入
即使是很小的程序,输入域也大到近乎无穷
测试的本质是从输入域中选取有限的值集合
输入参数定义了输入域的范围,包括:
- 方法的参数
- 从文件中读取的数据
- 全局变量
- 用户级别的输入
每个输入参数的域被划分为若干区域
从每个区域中至少选取一个值
划分域
划分域
- 域 D
- D 的划分方案 p
- 划分 p 定义了一组块:b₁, b₂, … bₙ
- 划分必须满足两个性质:
- 互不相交:各块之间没有重叠
- 完全覆盖:所有块合在一起覆盖整个域 D
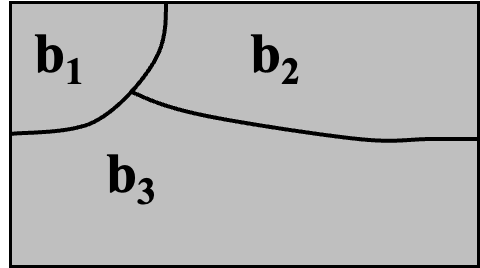
假设前提 等价性
即同一等价类中的所有值,对于测试目的而言行为相同
两种方法
- 基于接口的方法
- 直接从各个输入参数中提取特征
- 应用最简单
- 在某些场景下可以部分自动化
- 基于功能的方法
- 从被测程序的行为视角提取特征
- 开发难度更高,需要更多设计工作
- 可能产生更好的测试,或用更少的测试达到同等效果
基于接口的方法
单独考察每个参数(机械式处理)
这是一种简单的建模技术,主要依赖语法
忽略参数之间的关系
TriTyp 三角形类型判断程序
TriTyp 输入的第一次特征化(TriTyp 有三个整型输入)
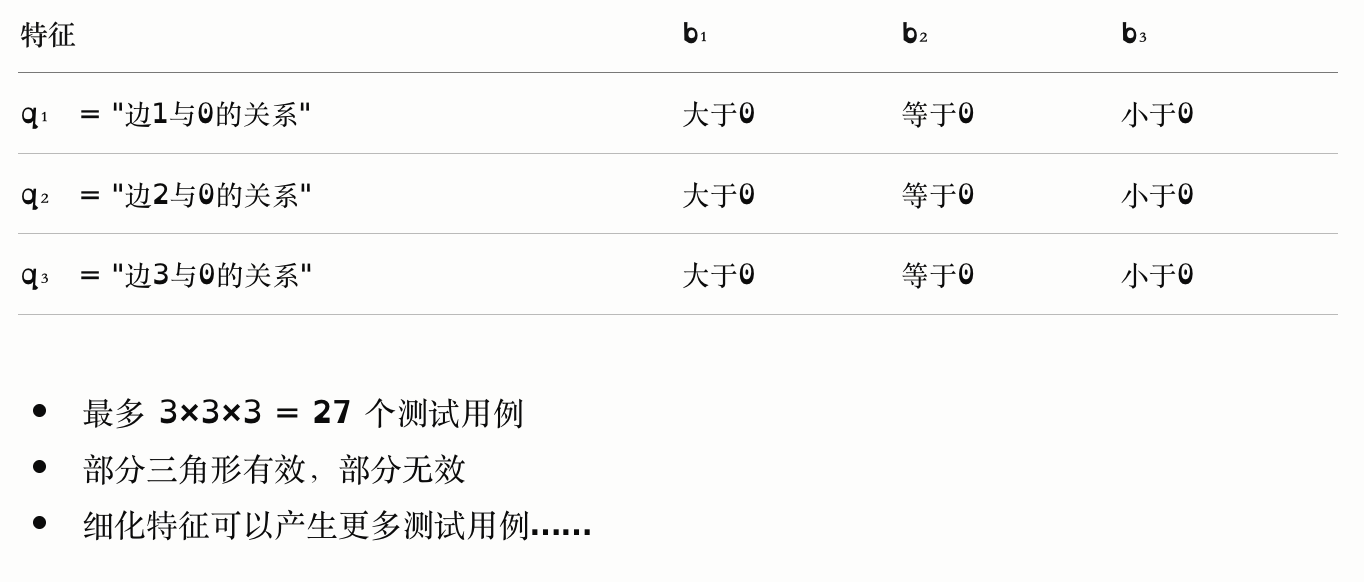
TriTyp 输入的第二次特征化
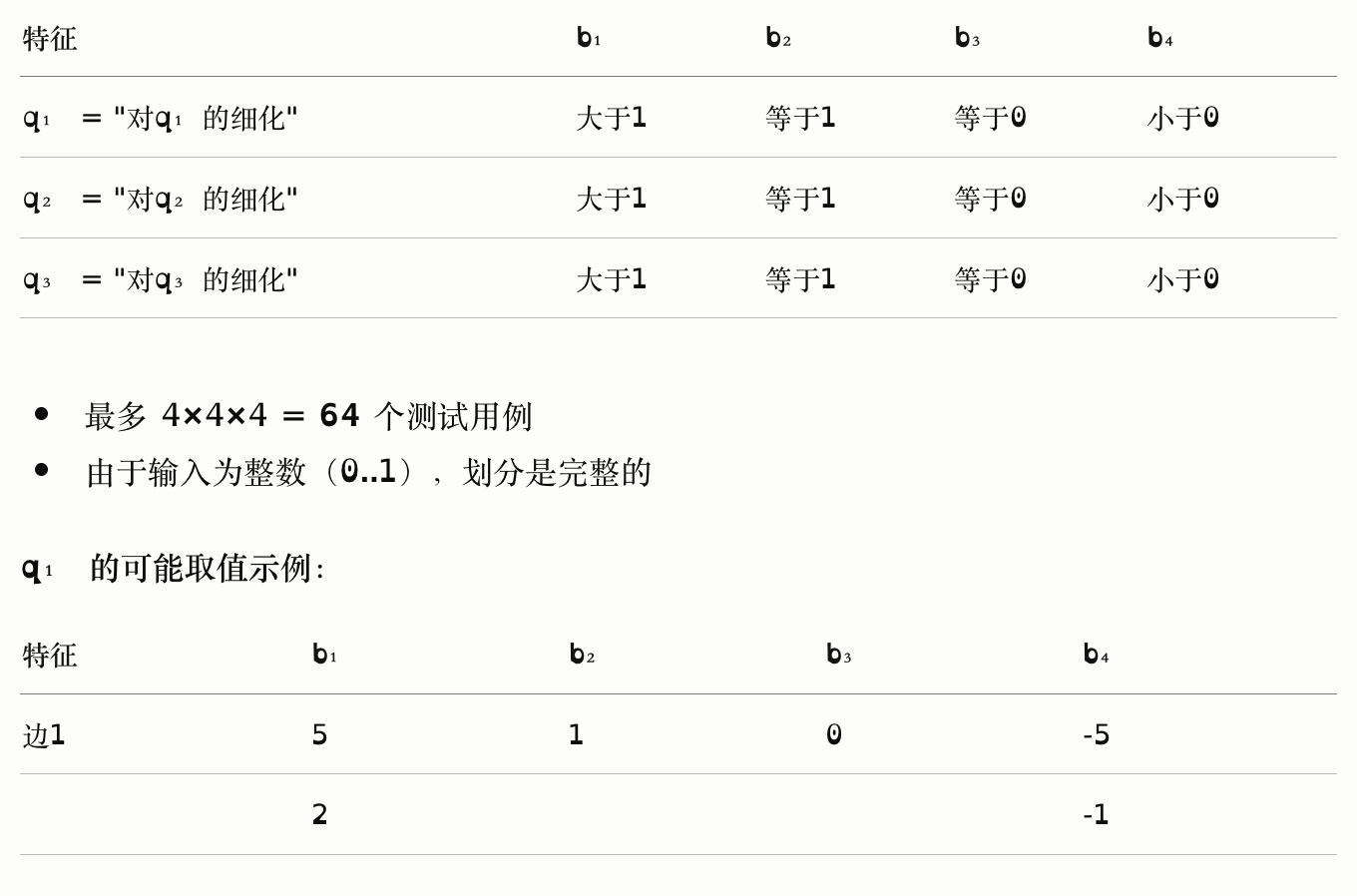
基于功能的方法
-
识别与预期功能相对应的特征
-
需要测试人员投入更多设计工作
-
可以融入领域知识和语义知识
-
可以利用参数之间的关系
-
建模可以基于需求而非实现
-
同一参数可能出现在多个特征中,因此将值转化为测试用例较为困难
以 TriTyp 为例,三个参数代表一个三角形:
合理的特征:三角形的类型
- 前两种特征化基于语法——参数及其类型
- 语义层面的特征化可以利用"三个整数代表一个三角形"这一事实
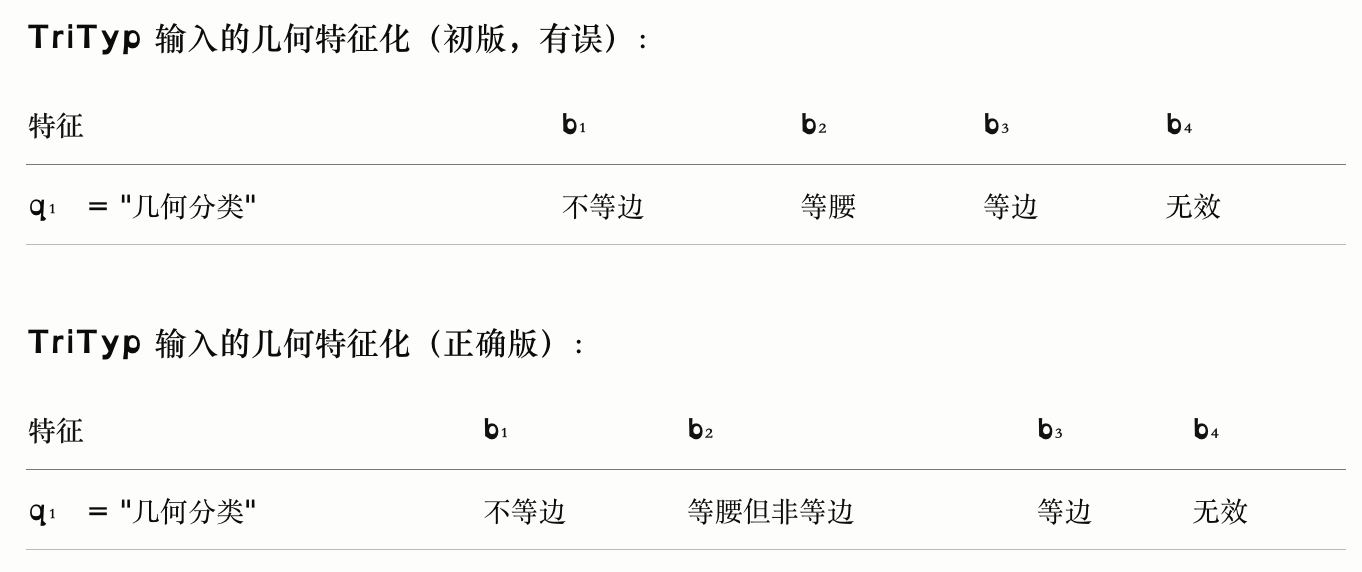
初版中"等腰"未排除"等边"的情况,导致块之间存在重叠,不满足互不相交的性质,故需修正。
该划分的取值可选择如下:

分别对应:不等边三角形、等腰非等边、等边三角形、无效(不构成三角形)
边界值分析 Boundary-Value Analysis
等价类的边界处容易存在 Bug。
eg:
float SQRT(float x)
{
if(x <= 0)
Error;
else if(x == 0)
return 0;
else {
// 计算过程
return result;
}
}注意:x<=0 已经覆盖了 x==0 的情况,导致 else if(x==0) 永远不会被执行,这是一个边界处的逻辑错误。
等价类划分:
- 类(i):x < 0
- 类(ii):x ≥ 0
边界值:
- 类(i) 的边界值:0 和 -MAX
- 类(ii) 的边界值:0 和 +MAX
测试用例:
- -MAX
- -MIN
- 0
- +MIN
- +MAX
原本只需 2个 测试用例(覆盖两个等价类),但为了覆盖边界需要额外增加测试。
| 类型 | 边界测试用例 |
|---|---|
| 字符串 | 最短长度-1 / 最大长度+1 |
| 示例:长度1~255 | 有效:1个字符、255个字符;无效:0个字符、256个字符 |
| 整数 | MIN-1 / MAX+1 |
| 示例:16位无符号整数 | 有效:0、65535;无效:-1、65536 |
| 循环 | 循环次数边界 |
for(int i=0; i<n; ++i) | |
for(int i=0; i<=n; ++i) | |
for(int i=1; i<n; ++i) |
数值范围参考表

字符与 ASCII 码对照表
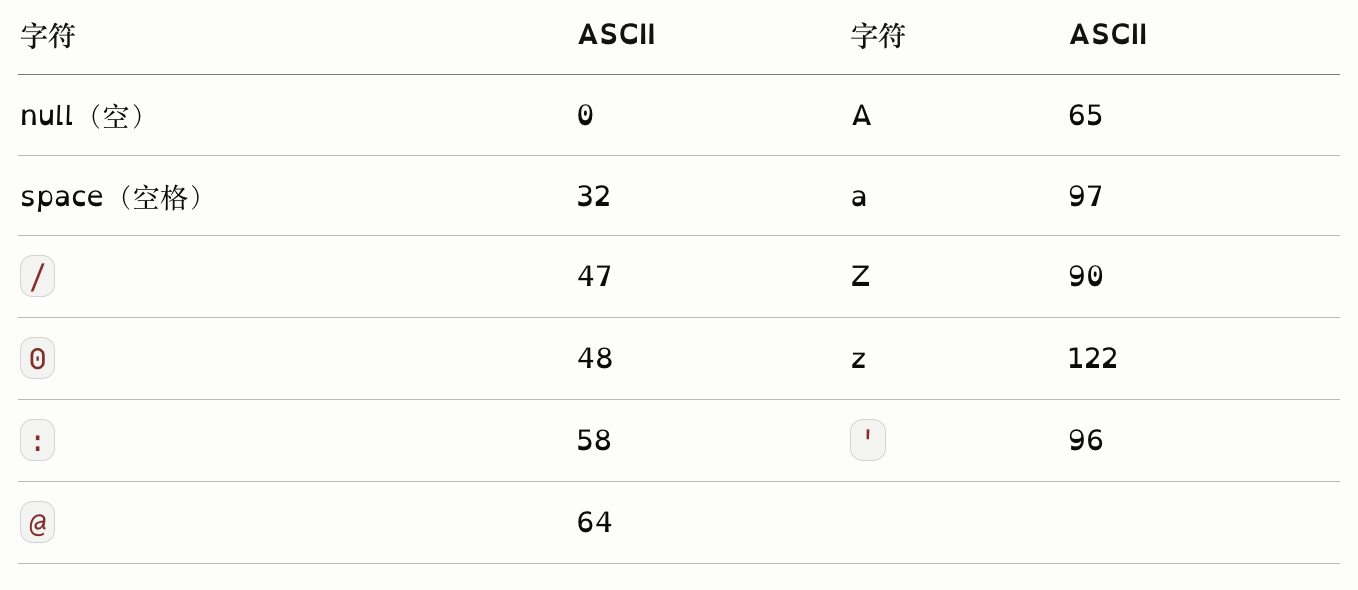
在字符类型的边界值测试中,需关注这些特殊字符的 ASCII 值边界。
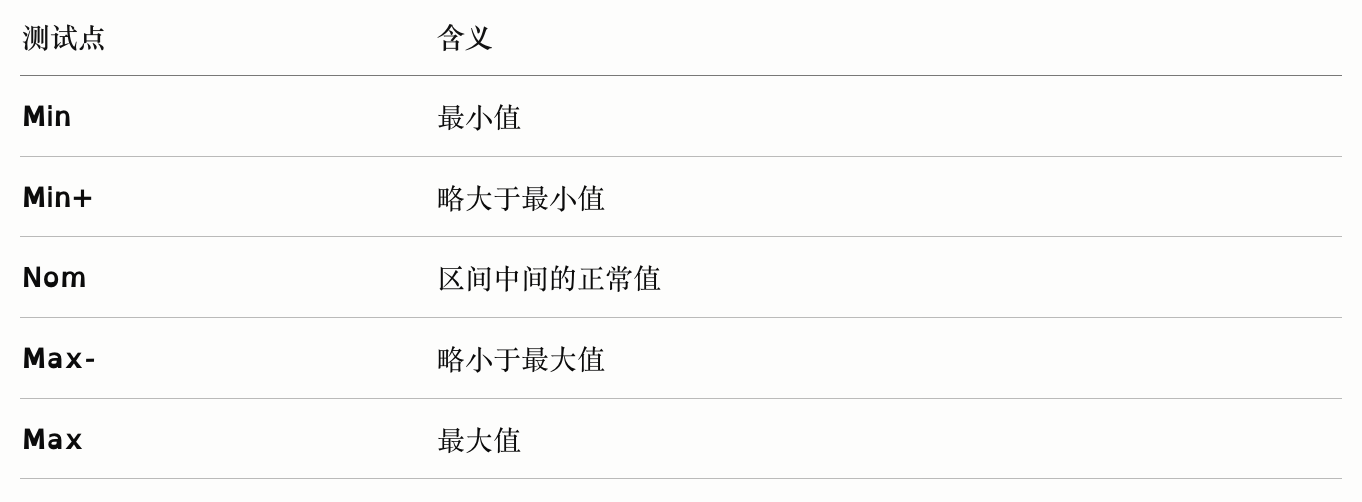
选取边界值
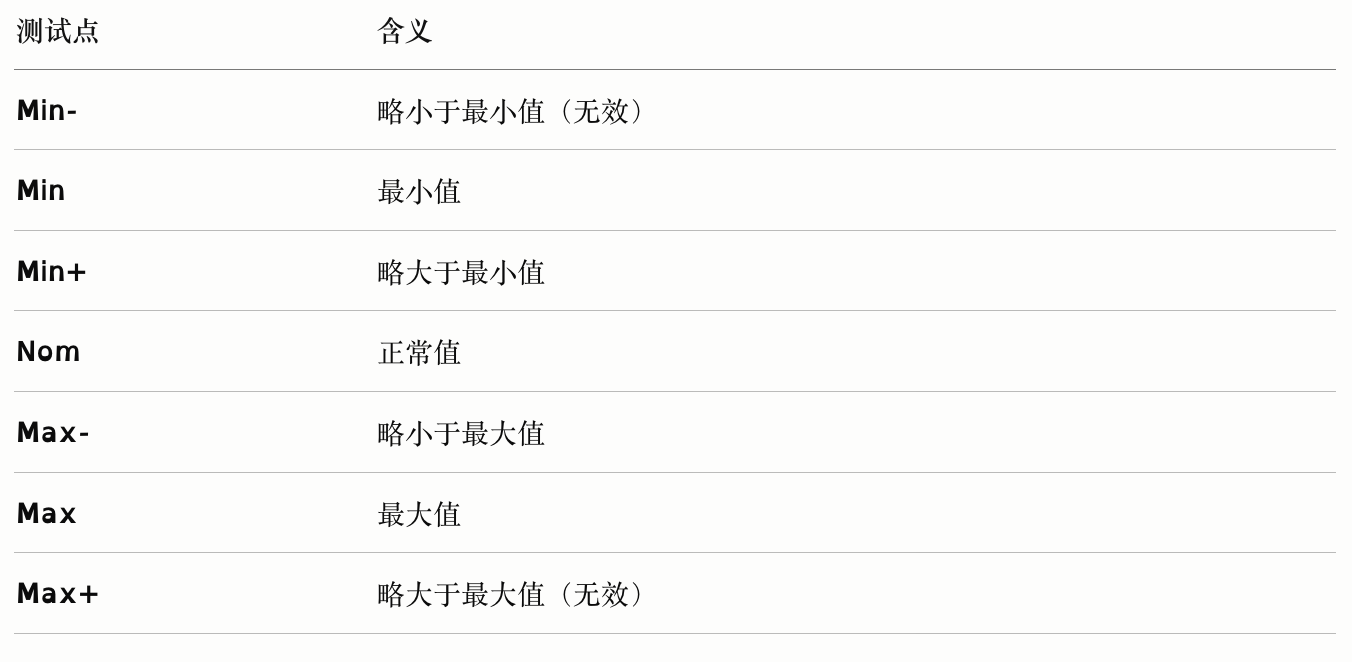
对于等价区间为 [Min, Max] 的输入变量,选取以下边界测试点:
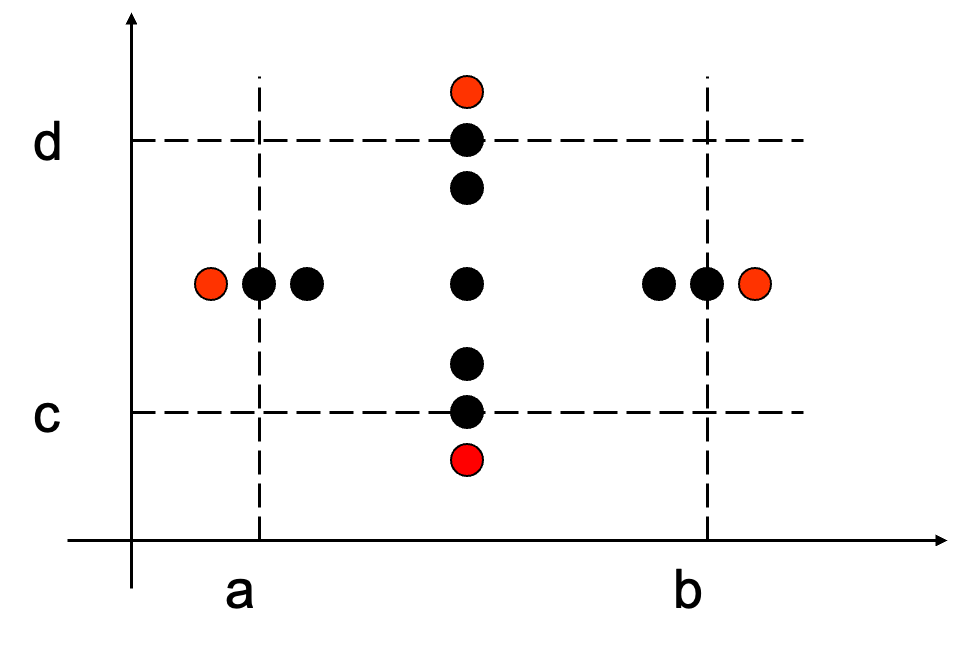
选取边界值(双变量示例)
以两个输入变量 x₁(a ≤ x₁ ≤ b)和 x₂(c ≤ x₂ ≤ d)为例,测试用例包括:
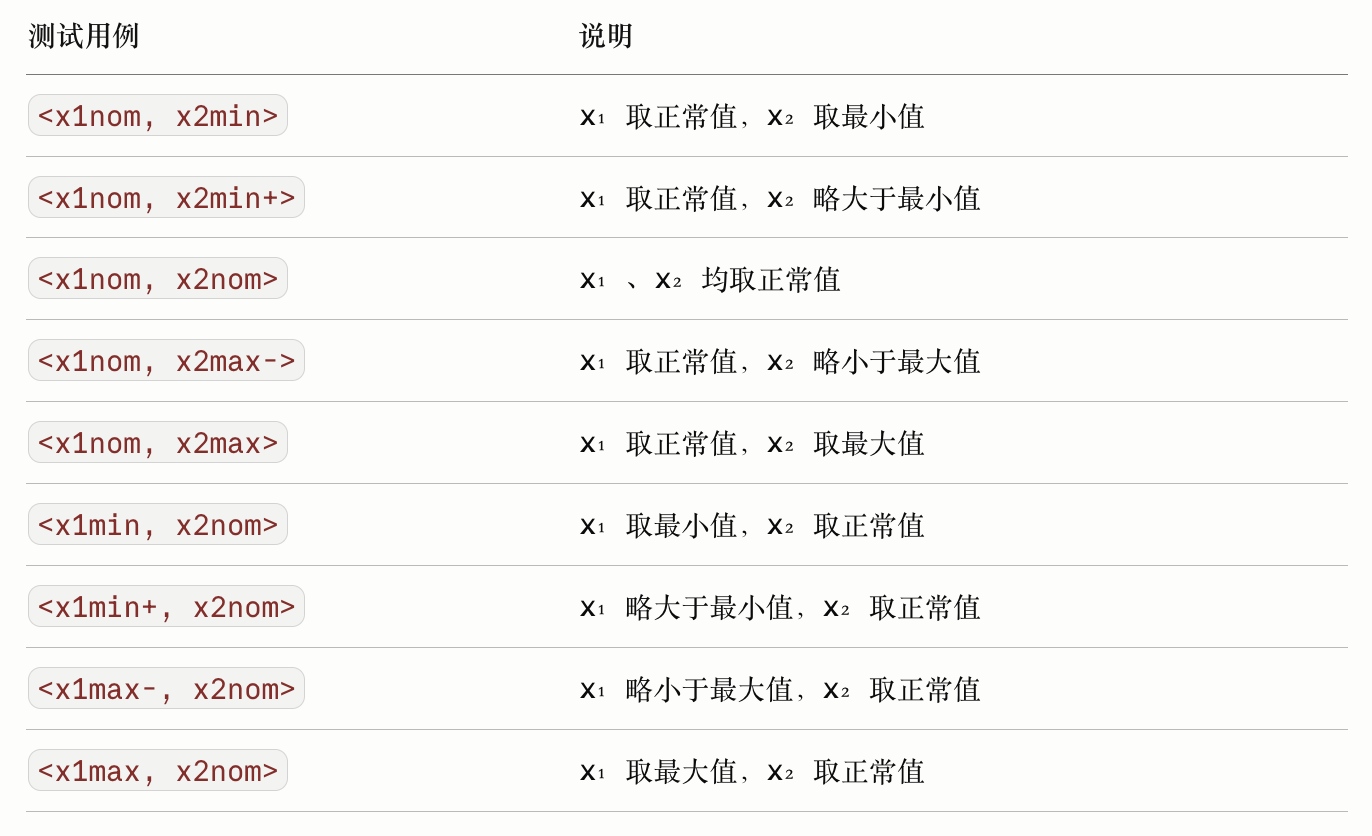
核心策略:每次只让一个变量取边界值,其余变量取正常值(Nom)。
数字类型测试用例示例
要求:输入6位正整数,测试用例如下:
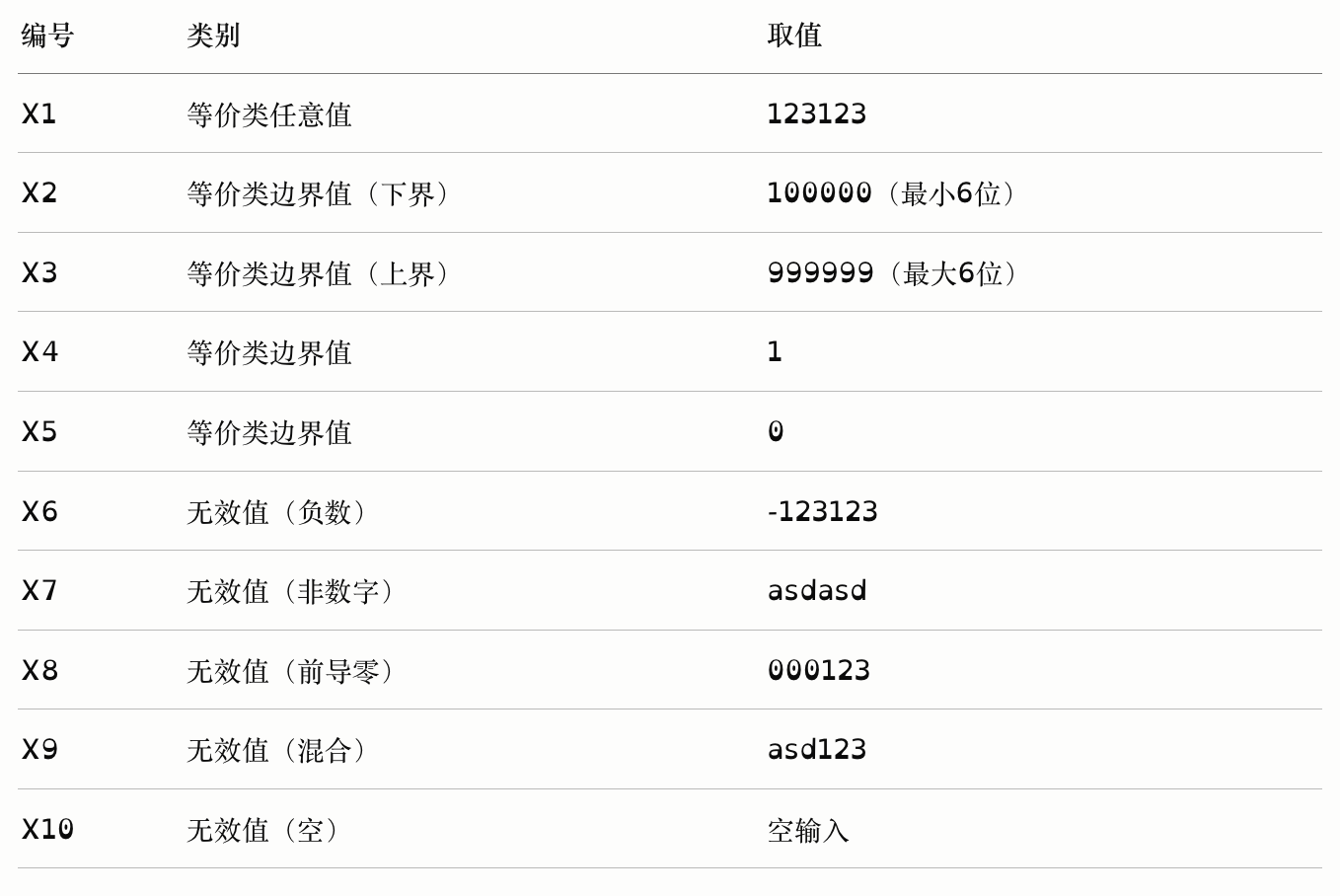
弱边界分析 Weak Boundary Analysis
策略:每次只让一个变量处于边界,仅考虑有效边界值(不含无效值),测试用例数量较少。
选取边界值(含无效值)
对于等价区间为 [Min, Max] 的输入变量,增加无效边界点后选取:
弱健壮边界分析 Weak Robust-Boundary Analysis
以两个输入变量 x₁(a ≤ x₁ ≤ b)和 x₂(c ≤ x₂ ≤ d)为例:
TriTyp 的边界分析
TriTyp(a, b, c),约束条件:
- 1 ≤ a ≤ 100
- 1 ≤ b ≤ 100
- 1 ≤ c ≤ 100
| 变量 | 测试取值集合 |
|---|---|
| a | {0, 1, 2, 50, 99, 100, 101} |
| b | {0, 1, 2, 50, 99, 100, 101} |
| c | {0, 1, 2, 50, 99, 100, 101} |
包含 Min-(0)、Min(1)、Min+(2)、Nom(50)、Max-(99)、Max(100)、Max+(101)七个测试点。
NextDate 的边界分析
月份范围:[1, 12]
日期范围(按月份):
| 月份 | 日期范围 |
|---|---|
| 1、3、5、7、8、10、12月 | [1,31] |
| 4、6、9、11月 | [1,30] |
| 平年2月 | [1, 28] |
| 闰年2月 | [1, 29] |
强边界分析 Strong Boundary Analysis
策略:对所有变量的边界值取笛卡尔积,即每个变量都同时取所有边界点,测试用例数量远多于弱边界分析。
TriTyp 的强边界分析
TriTyp(a, b, c),约束条件:
- 1 ≤ a ≤ 100
- 1 ≤ b ≤ 100
- 1 ≤ c ≤ 100
| 变量 | 测试取值集合 |
|---|---|
| a | { 1, 2, 50, 99, 100} |
| b | { 1, 2, 50, 99, 100} |
| c | { 1, 2, 50, 99, 100} |
测试集合 = a × b × c = {1, 2, 50, 99, 100} × {1, 2, 50, 99, 100} × {1, 2, 50, 99, 100}
共 5 × 5 × 5 = 125 个测试用例。
强健壮边界分析 Strong Robust-Boundary Analysis
以两个输入变量 x₁(a ≤ x₁ ≤ b)和 x₂(c ≤ x₂ ≤ d)为例:
在强边界分析基础上,同时加入无效边界值(Min- 和 Max+),并对所有变量取笛卡尔积。
测试用例数量最多,覆盖最全面,但成本也最高。
NextDate 的边界分析 (强边界)
NextDate(Day, Month, Year),约束条件:
- 1 ≤ day ≤ 31
- 1 ≤ month ≤ 12
- 1900 ≤ year ≤ 2012

每个变量包含 Min-、Min、Min+、Nom、Max-、Max、Max+ 共7个测试点。
边界知识小结
| 概念 | 含义 |
|---|---|
| Boundary(边界) | 等价类之间的分界线/分界点 |
| Boundary Values(边界值) | 位于边界附近的具体取值(Min、Max 等) |
| Boundary Analysis(边界分析) | 系统地选取边界值作为测试用例的方法 |
组合测试预热 Combinatorial Testing
回顾:输入域测试方法
- 随机测试(Random Testing)
- 等价类划分(Equivalence Partitioning)
- 边界值分析(Boundary-Value Analysis)
当前的问题:上述方法未能有效处理输入变量之间的关系。
回顾:基于模型的测试
决策表测试(Decision Tables)
- 能够考虑输入变量与输出变量之间的关系
- 问题:难度较大
- 提取变量间关系本身就很困难
- 如何描述这些关系也是一大挑战
弱等价类测试 Weak Equivalence Class Testing
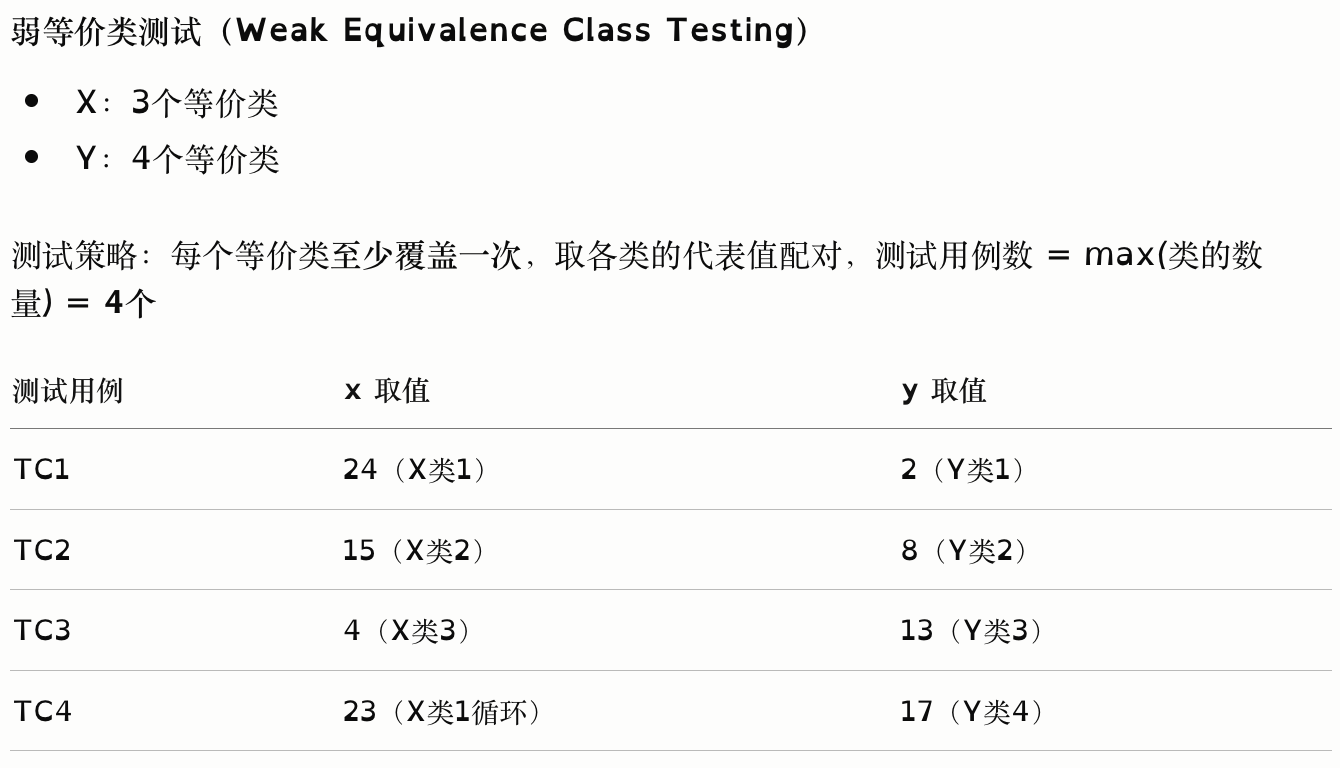
弱等价类测试:用最少的测试用例覆盖所有等价类,不做笛卡尔积。
强等价类测试 Strong Equivalence Class Testing
- X: 3个等价类
- Y: 4个等价类
测试策略:对所有等价类取笛卡尔积,测试用例数 = 3 × 4 = 12个
覆盖 X 和 Y 每个等价类的所有组合,测试更充分但成本更高。
坐标示意图中:X 轴分为 [1,5)、[5,10)、[10,20) 三类;Y 轴分为 [1,10)、[10,20)、[20,30)、[30,+) 四类。
高性价比测试 Cost Effective Testing
- 强等价类测试(笛卡尔积)覆盖全面,但测试用例数量爆炸式增长
- 弱等价类测试用例少,但可能遗漏变量间的交互缺陷
- 如何在测试成本与缺陷检测能力之间取得平衡?
组合测试示例
有4个输入,各自的等价类:
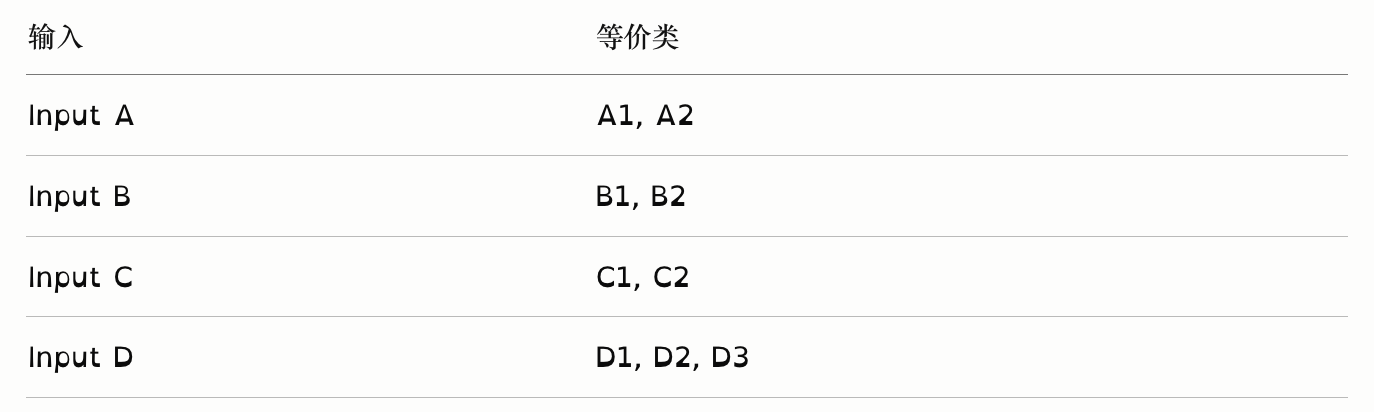
弱等价类测试 取 max = 3 个测试用例

每个等价类至少出现一次,用例数 = max(2, 2, 2, 3) = 3个,但变量间的组合关系未被充分覆盖。
组合测试 Combinatorial Testing
核心思想:通过系统地组合输入变量的各等价类值,在有限的测试用例中尽可能覆盖变量间的交互关系。
全组合测试 All Combinations
对所有参数值的可能组合全部测试:
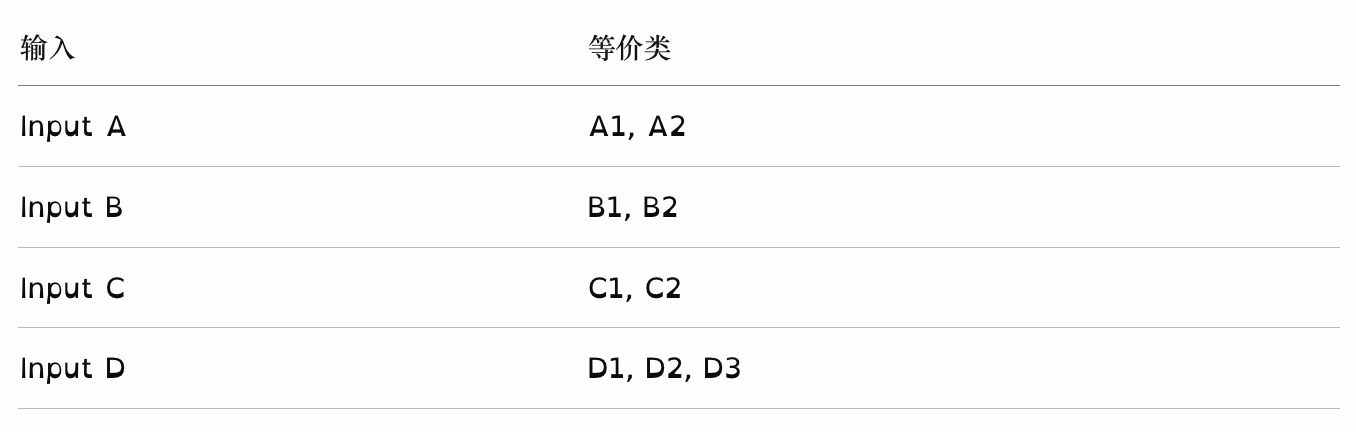
总测试用例数 = 2 × 2 × 2 × 3 = 24个
覆盖最全面,但成本极高,实际项目中几乎不可行。
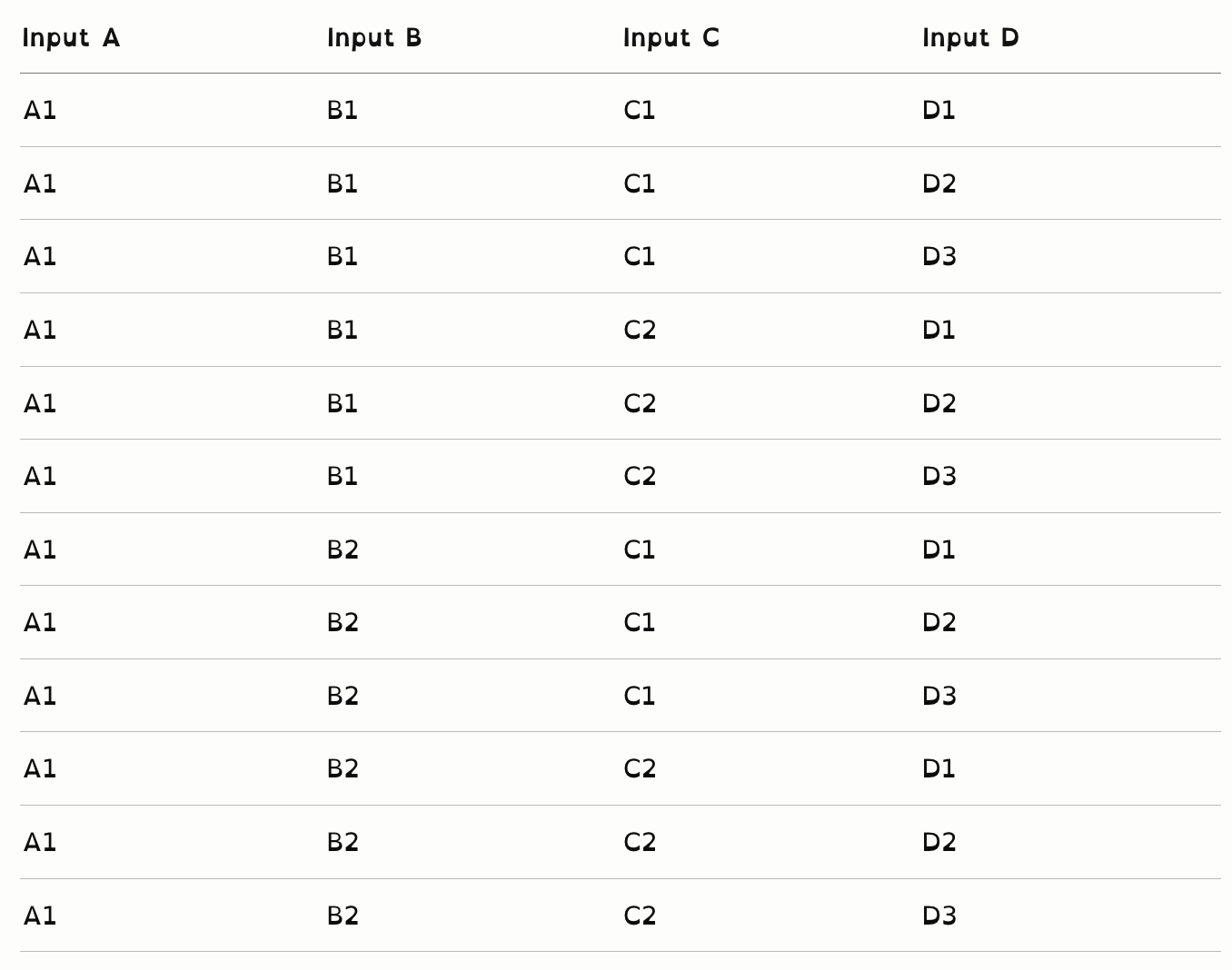
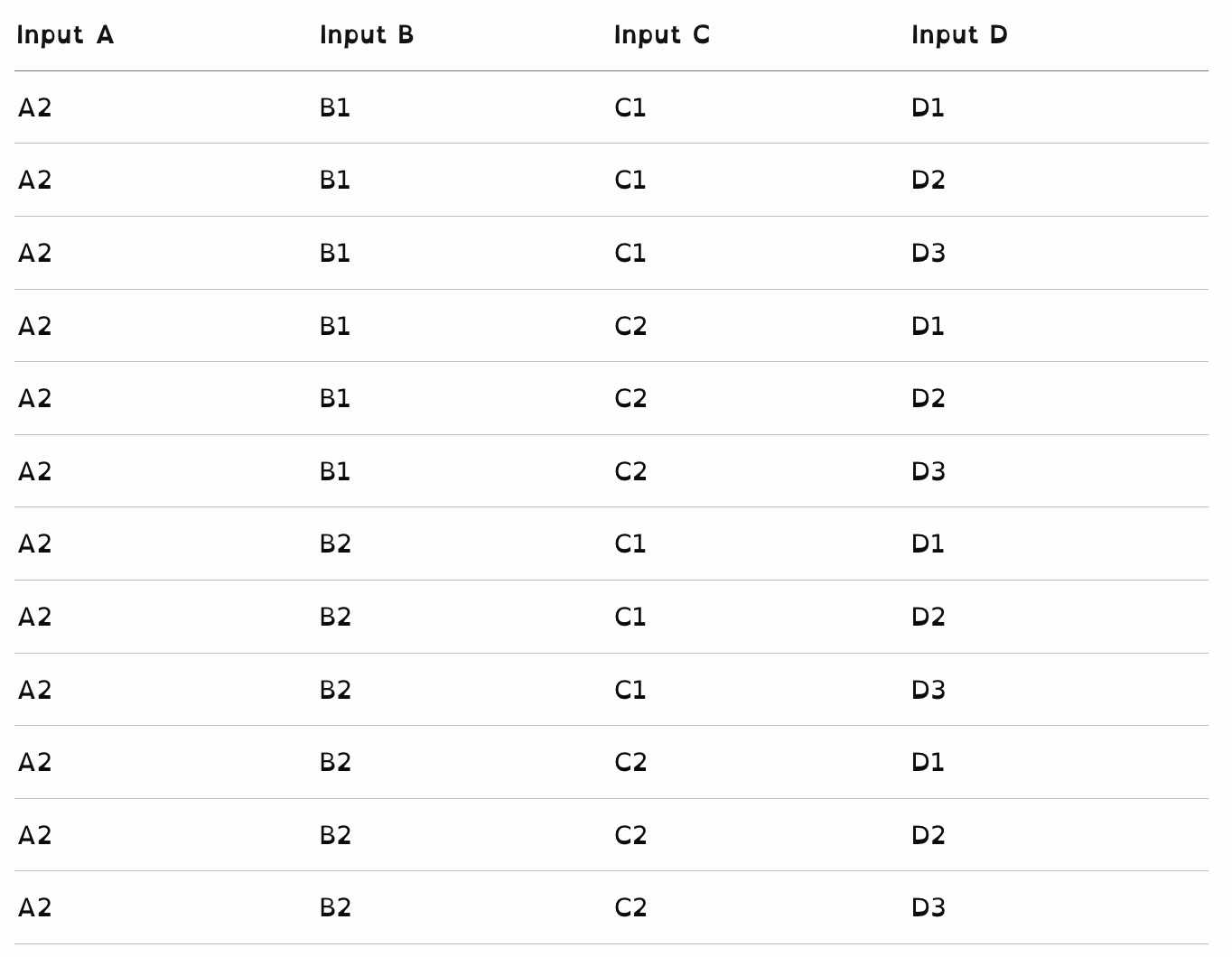
全组合测试用例完整列表
A1组(12个):
A2组(12个):
成对测试 Pair-wise Testing
策略:确保任意两个输入变量的所有取值组合至少出现一次,大幅减少测试用例数量。
仅需 6个 测试用例:

从24个减少到6个,覆盖了所有两两组合,性价比极高。
t-wise / t-ways 组合测试
策略:确保任意 t 个输入变量的所有取值组合至少出现一次。
当 t = 3 时,需要 12个 测试用例:
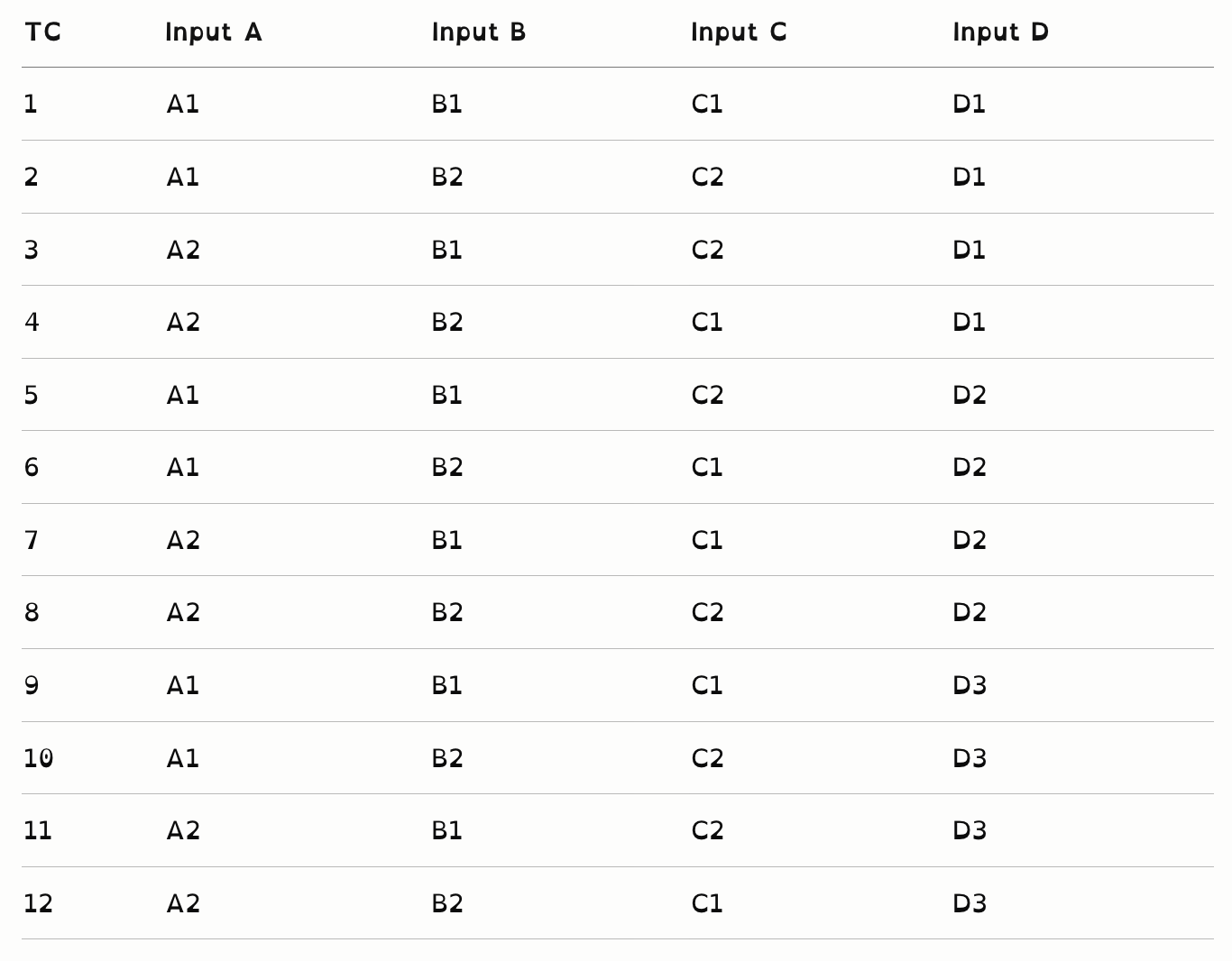
t 值越大,覆盖越全面,用例数越多(介于成对测试和全组合之间)。
组合测试方法汇总
组合测试
├── 固定强度组合测试(Fixed Strength)
│ ├── 成对测试(Pair-wise,t=2)
│ └── t-way 组合测试(t=3, 4, ...)
└── 可变强度组合测试(Variable Strength)核心问题:
- 在全组合中进行采样
- 不考虑输入变量的特殊信息(即把所有变量一视同仁)
可变强度组合测试 Variable Strength Combinatorial Testing
核心思想:根据实际情况,对不同的变量组合设定不同的覆盖强度。
交互关系定义:
R = { {Input A, Input B, Input C},
{Input A, Input D},
{Input C, Input D} }即:A+B+C 之间需做3-wise覆盖,A+D 之间需做2-wise,C+D 之间需做2-wise。
生成的测试用例(9个):
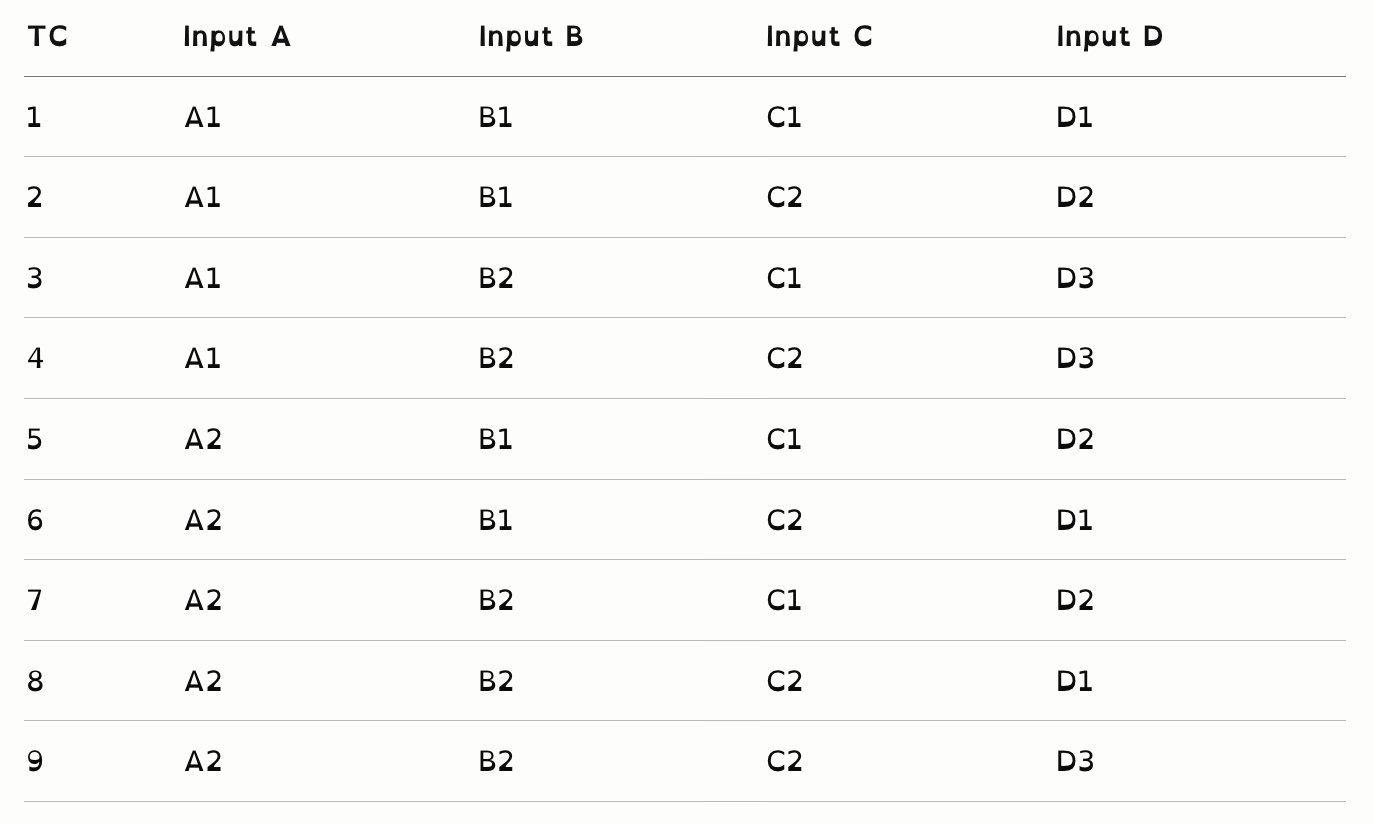
比固定强度的12个用例少,同时针对重点变量组合做了更有针对性的覆盖。