黑盒测试 Blackbox Testing
随机测试 Random Testing
简单 = 强大 Simple = Powerful
随机不等于免费 Random != Free
随机不等于简单 Random != Simple
随机测试看起来简单,但真正做好并不容易。随机生成测试用例并不是“随便生成”,它仍然需要明确输入范围、随机策略和有效的自动化执行机制。
- 测试用例完全随机生成。
- 必须已知输入域。
- 在输入域中随机选取测试点。
- 自动化。
随机测试的核心是:先确定程序允许的输入范围,然后从这个范围中随机抽取输入作为测试用例。由于随机测试往往需要大量测试数据,因此通常依赖自动化执行。
int Add(const int &a,
const int &b)
{
return a+b;
}函数接收两个整数 a 和 b,返回它们的和。
用一个非常简单的加法函数作为例子,引出随机测试时“输入域”如何定义的问题。虽然函数很简单,但如果 int 有范围限制,比如 16 位整数或 32 位整数,那么随机输入就必须考虑这些边界。
即使是简单的 Add(a, b),输入空间也可能非常大。随机测试需要知道输入范围,例如:
a ∈ [-32768, 32767]
b ∈ [-32768, 32767]然后在这个范围内随机选择(a,b)
随机测试中的问题
定义输入域
随机机制
随机性与完整性服务:random.org
随机测试主要有几个问题:
- 必须定义输入域
- 必须设计随机机制
- 随机性本身也有质量问题
多样性 Diversity
均匀分布下的随机
随机测试希望测试用例具有多样性,也就是尽量覆盖输入空间中的不同区域。
但是如果使用均匀分布随机生成测试用例,可能会出现测试点聚集在某些区域,而另一些区域覆盖不足的问题。
因此,虽然随机测试简单,但它不一定能保证测试输入分布得足够“均匀有效”。
自适应随机测试 Adaptive Random Testing
它是在普通随机测试基础上的改进。普通随机测试每次直接随机选一个测试输入,而 ART 会尽量让新生成的测试输入远离已经执行过的测试输入,从而提高测试输入的分散性和多样性。
不只是随机选点,而是倾向于选择“离已有测试点更远”的随机点。
int Add(const int &a,
const int &b)
{
return a+b;
}如果把两个输入参数 a 和 b 看成二维坐标,那么:
a ∈ [-32768, 32767]
b ∈ [-32768, 32767]那么整个输入域就是一个二维平面区域。随机测试就是在这个区域中随机选择测试点。
ART Algorithm
randomly generate an input t, run t, add t to T
while (stop criteria not reached)
randomly generate k candidate input c1, … ck
for each candidate ci
compute min distance di to T
end for
select one candidate t with max distance
run t, add t to T
end while随机生成一个输入 t,运行 t,并将 t 加入测试集合 T
while(尚未达到停止条件)
随机生成 k 个候选输入 c1, …, ck
对每一个候选输入 ci:
计算 ci 到已有测试集合 T 的最小距离 di
end for
选择最小距离 di 最大的那个候选输入 t
运行 t,并将 t 加入测试集合 T
end whileART 的核心不是“随机生成一个就立刻用”,而是:
先随机生成多个候选测试输入,然后看哪个候选点离已有测试点最远,最后选择最远的那个作为真正执行的测试用例。
这样可以让测试用例在输入空间中分布得更分散。
ART 中的问题 Problems in ART
- 距离 Distance
- 开销 Overhead
- 维度灾难 Curse of Dimensionality
ART 虽然比普通随机测试更有策略,但也有问题:
第一,距离怎么定义
对于数值输入,距离可以用欧氏距离、曼哈顿距离等。但对于字符串、对象、文件、GUI 操作序列等复杂输入,距离就不容易定义。
第二,计算开销更大
普通随机测试生成一个输入就直接执行;ART 需要生成多个候选输入,并且计算它们与已有测试集合的距离,所以成本更高。
第三,维度灾难
当输入参数很多时,输入空间维度变高,距离计算和“分散性”的效果都会变差。二维空间中看起来很直观的“远近”,在高维空间里会变得复杂。
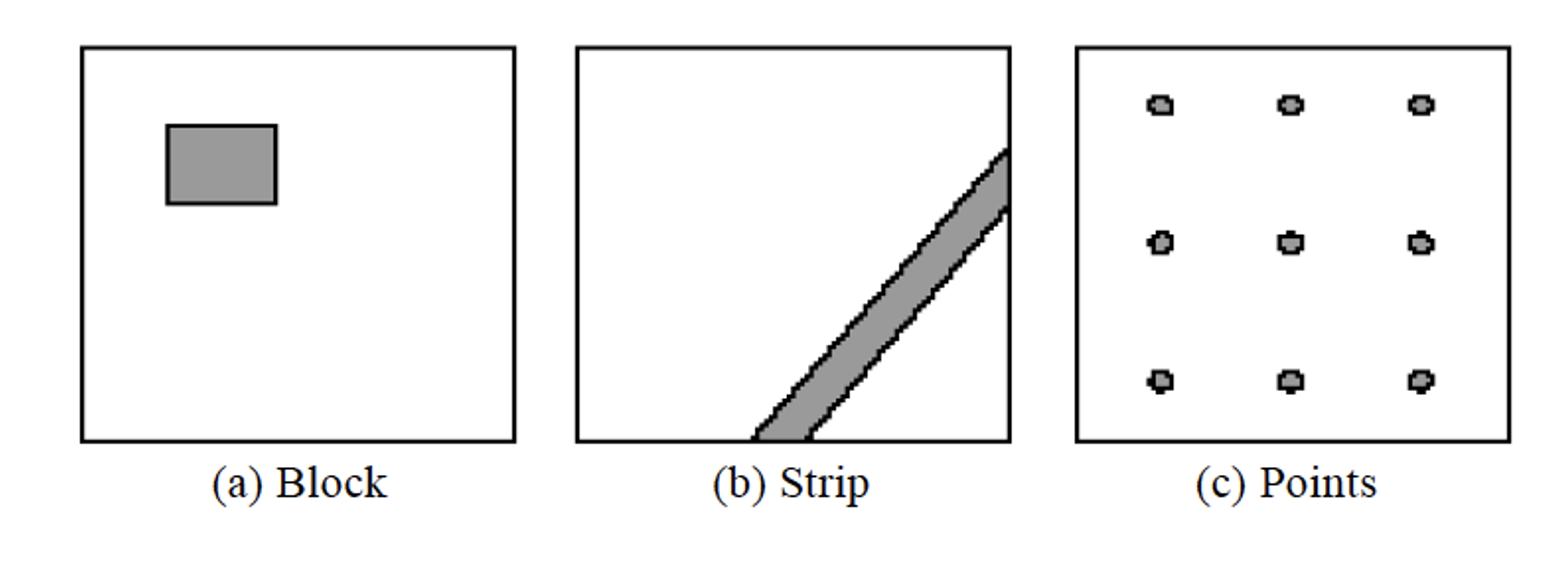
导致失败区域的典型模式
- 块状区域;
- 条带状区域;
- 点状区域;
- 多个分散的小区域。
在软件测试中,失败区域是指输入空间中能够触发程序失败(bug)的所有输入的集合。
如果失败区域比较“集中”或“成块”,那么让测试点更分散,通常更容易命中失败区域。
这里主要是在回答:随机测试什么时候有效,什么时候无效?