
数据流覆盖 Data Flow Coverage
数据流 Data Flow
超越结构覆盖
目标: 尽量确保变量的值被正确计算,并且被正确使用。
结构覆盖只关心“程序走没走到某些点或路径”,而数据流覆盖进一步关心“变量的定义和使用之间是否合理”。
Definition / def
变量的值被存入内存的位置。
也就是变量被赋值的位置。
Use
变量的值被访问的位置。
也就是变量被读取、参与计算或判断的位置。
eg:
X = 42; // 定义 X
Z = X - 8; // 使用 X,定义 Z
Z = X * 2; // 使用 X,重新定义 Z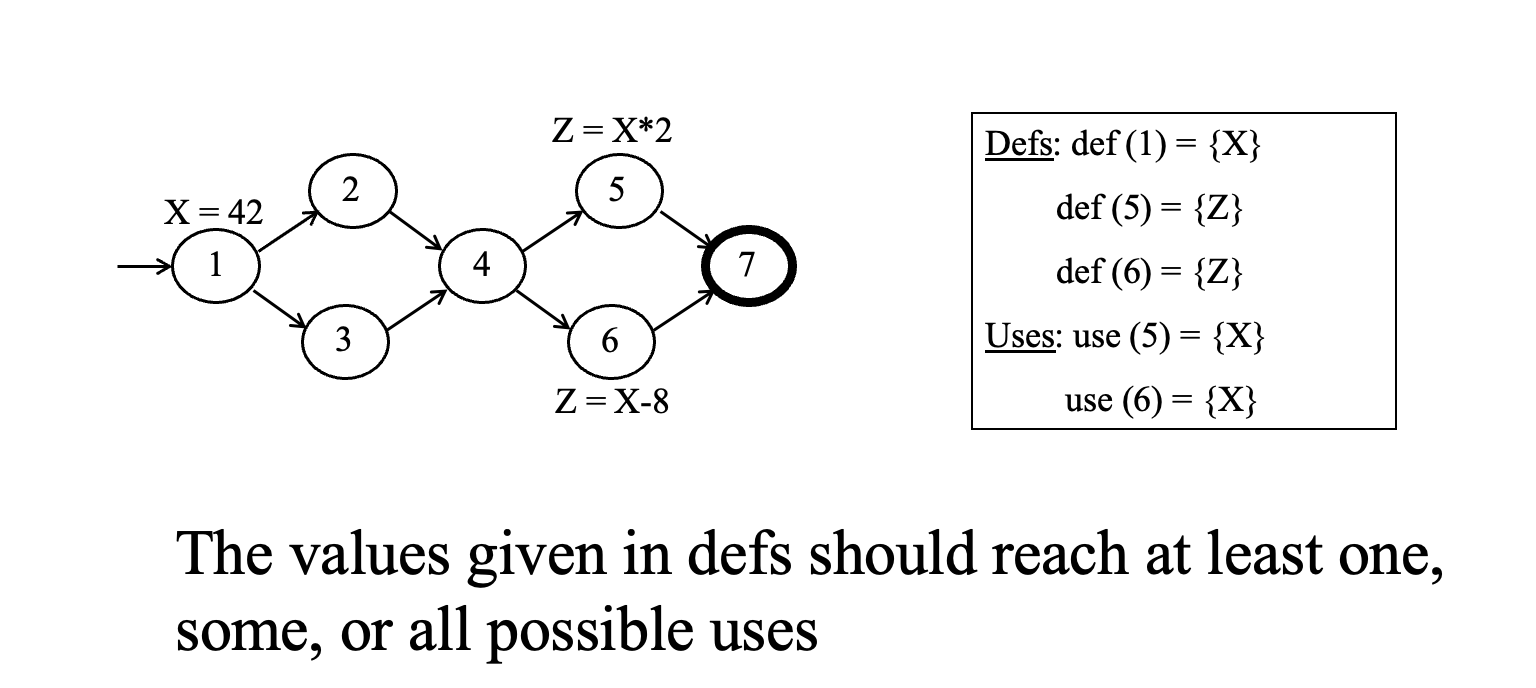
在定义点产生的值,应该至少能够到达某一个、某些,或者所有可能的使用点。
数据流图关注的是:一个变量在某处被赋值后,这个值有没有机会传播到后续真正使用它的地方。
定义集合和使用集合
def(n) or def(e):节点 n 或边 e 上被定义的变量集合。
use(n) or use(e):节点 n 或边 e 上被使用的变量集合。
其中:
- n 表示node节点
- e 表示edge边
有点变量的定义或是用发生在节点上,例如赋值语句。
有点变量的使用可能发生在边上,例如条件判断。
if (i < length)DU 对 DU Pair
DU pair: 一个位置对(li,lj),其中变量v在位置li被定义,在位置lj被使用。
DU 对是“变量定义点”和“变量使用点”之间形成的一对位置。
eg:
x = 10; // 定义 x
y = x + 1; // 使用 x这里就存在一个关于变量x的DU pair: (def of x, use of x)
定义清晰路径 / 无重定义路径 Def-clear
Def-clear:如果从 li 到 lj 的路径上,变量 v 没有在任何节点或边上被重新赋值,那么这条路径对于变量 v 来说就是 def-clear 的。
从定义点到使用点之间,变量没有被重新定义,这条路径就是 def-clear path。
Reach:如果从 li 到 lj 存在一条关于变量 v 的 def-clear 路径,那么就说 li 处对变量 v 的定义可以到达 lj 处的使用。
更直观的展示:
x = 1; // li:定义 x
...
y = x + 1; // lj:使用 x如果中间没有再次给 x 赋值,那么 x = 1 这个定义就可以到达 y = x + 1 这个使用点。
如果一条路径上不存在变量 v 的重新定义,那么这条路径相对于变量 v 来说就是定义清晰路径,也就是 def-clear path。
判断 def-clear 时,只关心指定变量 v 有没有被重新定义。 其他变量是否被定义不影响该变量的 def-clear 判断。
DU 路径 DU Path
du-path: 从变量v的一个定义点到变量v的一个使用点之间,一条关于v是def-clear的简单子路径。
DU path同时满足3个条件:
- 从变量的定义点出发;
- 到变量的使用点结束;
- 中间没有重新定义该变量;
- 是 simple subpath,即简单子路径。
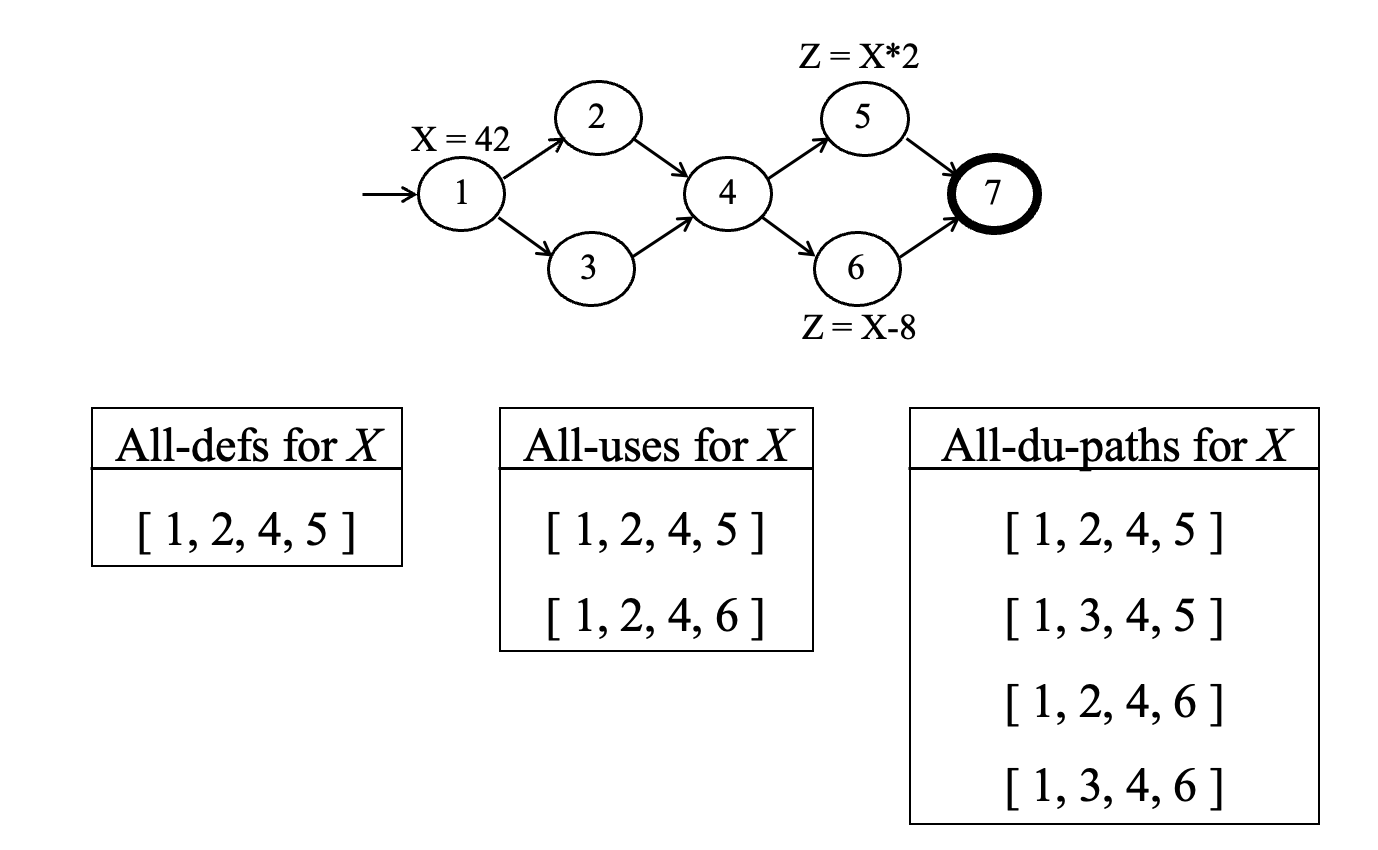
du(ni,nj,v):从节点ni到节点nj,关于变量v的所有DU路径集合。
强调的是某一个定义点到某一个使用点之间的路径集合。
du(ni,v):从节点ni出发,关于变量v的所有DU路径集合。
强调的是从某个定义点出发,变量 v 能到达的所有使用点对应的路径集合。
数据流覆盖 = 在控制流图的基础上,关注变量从“定义 def”到“使用 use”的传播过程。
def:变量被赋值
use:变量被读取
DU pair:定义点和使用点组成的一对位置
def-clear:定义到使用之间没有重新定义
DU path:从 def 到 use 的 def-clear 简单路径数据流覆盖准则 Data Flow Coverage Criteria
全定义覆盖 All-defs coverage,ADC
对于每一个 DU 路径集合:S = du(n, v)
测试需求集合 TR 中至少包含 S 里面的一条路径 d。
对于每一个变量定义点,至少要覆盖一条从该定义点出发、到某个使用点的 DU 路径。
重点是 每个定义点至少用到一次。
全使用覆盖 All-uses coverage,AUC
对于每一个从定义点 ni 到使用点 nj 的 DU 路径集合:S = du(ni, nj, v)
测试需求集合 TR 中至少包含 S 里面的一条路径 d。
对于每一个定义-使用对,至少覆盖一条从定义到该使用点的 DU 路径。
重点是 每个定义-使用关系都要覆盖一次。
全 DU 路径覆盖 All-du-paths coverage,ADUPC
对于每一个 DU 路径集合:S = du(ni, nj, v)
对于每一个定义-使用对,所有可能的 DU 路径都要覆盖。
覆盖关系强度一般是:
All-du-paths coverage > All-uses coverage > All-defs coverageeg:
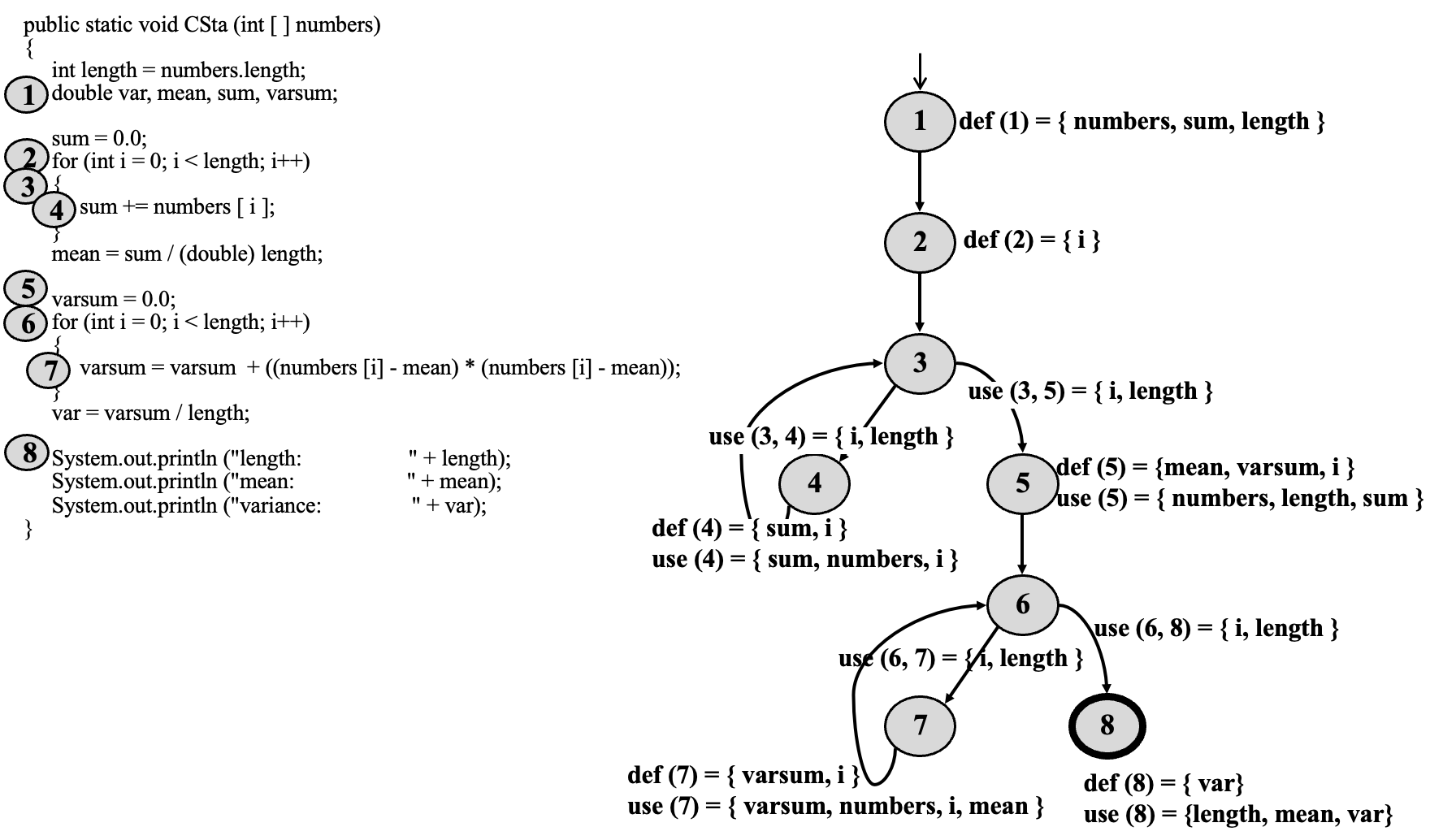
节点1: def(1) = { numbers, sum, length }
节点2: def(2) = { i }
节点3: for循环的i < length条件
节点4: def(4) = { sum, i } use(4) = { sum, numbers, i }对应循环体,sum += numbers[i]; i++;
节点5: def(5) = { mean, varsum, i } use(5) = { numbers, length, sum,代表mean = sum / (double) length; varsum = 0.0; int i = 0;
节点6: for 循环的i < lenght条件
节点7: def(7) = { varsum, i } use(7) = { varsum, numbers, i, mean },对应第二个循环体varsum = varsum + ((numbers[i] - mean) * (numbers[i] - mean)); i++;
节点8: def(8) = { var } use(8) = { length, mean, var }
节点变量列表
| Node | Def | Use |
|---|---|---|
| 1 | { numbers, sum, length } | { numbers } |
| 2 | { i } | |
| 3 | ||
| 4 | { sum, i } | { numbers, i, sum } |
| 5 | { mean, varsum, i } | { numbers, length, sum } |
| 6 | ||
| 7 | { varsum, i } | { varsum, numbers, i, mean } |
| 8 | { var } | { length, mean, var } |
边变量列表
| Edge | Use |
|---|---|
(1, 2) | |
(2, 3) | |
(3, 4) | { i, length } |
(4, 3) | |
(3, 5) | { i, length } |
(5, 6) | |
(6, 7) | { i, length } |
(7, 6) | |
(6, 8) | { i, length } |
测试路径
ADC:每个定义至少到一个使用
AUC:每个定义-使用对至少覆盖一条路径
ADUPC:每个定义-使用对的所有 DU 路径都覆盖
强度关系:ADUPC ≥ AUC ≥ ADC
事件流图 Event Flow Graph
事件流图的形式化定义
事件流图EFG是一个三元组:
M = ⟨V, I, E⟩
v是顶点集合,表示对象的所有事件。
也就是说,每个顶点代表一个 GUI 事件,例如点击按钮、选择菜单、输入文本等。
I是初始顶点集合,并且I是V的子集。
也就是说,I 表示哪些事件可以作为测试序列的起始事件。
E是边集合,是V × V的子集。
边表示事件之间的先后执行关系。
边的含义
当且仅当事件 vj 可以紧接在事件 vi 之后执行时,边 (vi, vj) 属于 E。
如果用户执行完事件 vi 后,可以马上执行事件 vj,那么图中就存在一条从 vi 到 vj 的边。
事件流图的例子
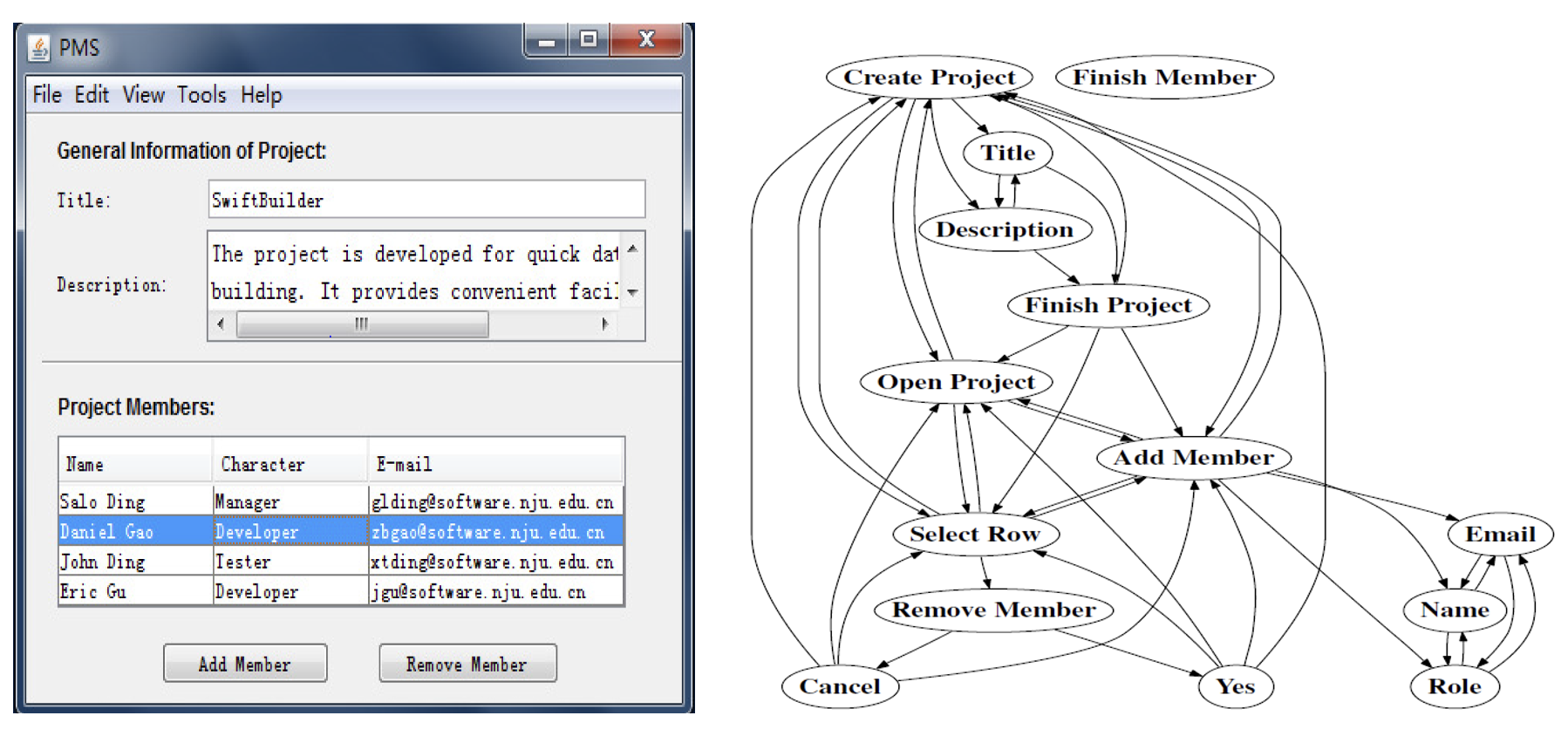
GUI 中的事件不是孤立的,而是存在合法的执行顺序。
例如在一个查找 / 替换窗口中:
输入查找内容 → 点击 Find next
输入查找内容 → 点击 Replace
输入查找内容 → 点击 Replace all
点击 Cancel → 关闭窗口GUITAR
GUITAR 是基于 EFG 的自动化测试框架
GUITAR 包含四个子系统:
GUIRipper
GUI 对象提取。作用是自动分析程序界面,提取窗口、按钮、菜单、文本框等 GUI 对象信息。
GUIStructure2Graph
构造事件流图。作用是根据提取出的 GUI 结构,推断事件之间的可执行关系,并生成 EFG。
TestCaseGenerator
基于 EFG 生成测试用例。作用是遍历事件流图,根据覆盖准则生成事件序列。
GUIReplayer
运行测试。作用是根据生成的测试用例,自动回放 GUI 操作序列。